

Table of Contents
Don't have the time to read the entire post? Our human writers will be sad, but we understand. Summarize the post with your preferred LLM here instead.
This tutorial was written by Vivek Kumar Maskara, a Senior Software Engineer who is passionate about coding, building apps, and solving real-world problems. Visit Vivek's website to see more of his work!
When evaluating LLM apps, it's easy to become frustrated when the same input produces different outputs. This is especially true in RAG systems, since there's an extra moving part (the retriever) that fetches relevant documents or context based on the user query; failures can come from the retrieval-generation pipeline instead of the model itself. This added complexity makes testing difficult, as you’re no longer validating deterministic outputs but evaluating the quality and consistency of probabilistic behavior.
How you evaluate frameworks matters. Frameworks like DeepEval, RAGAS, and LangSmith give you a repeatable way to measure answer quality, retrieval quality, hallucination risk, and overall behavior before you ship changes to production.
This article compares these frameworks through a practical, hands-on evaluation exercise to help developers choose the right framework for their team's workflow, technical requirements, and evaluation needs. We'll look at design philosophy, metric coverage, workflow fit, learning curve, and pricing.
Design philosophy: how each framework handles evaluation
DeepEval, RAGAS, and LangSmith are built around different ideas of what evaluation should look like. DeepEval treats evaluation like testing, where you define test cases and check whether outputs meet expected behavior with clear pass or fail signals. RAGAS treats it more like a measurement, focusing on scoring different aspects of a RAG system, like whether the answer is grounded in the retrieved context or whether the right documents were retrieved. LangSmith takes a broader approach, where evaluation is part of a larger workflow that includes tracing, debugging, and comparing runs over time.
DeepEval: evaluations as unit tests
DeepEval's core idea of LLM evaluation is quite close to how you would test traditional software. Instead of thinking in terms of abstract scoring, it frames evaluations as test cases: you define an input, an expected output, and any supporting context, then run metrics that act like assertions. This makes it feel familiar, especially if you're used to automated testing, and a natural fit for CI checks, regression prevention, and pass/fail quality gates.
This testing-based approach helps teams encode expected behavior directly into their workflow and catch regressions when prompts, retrievers, models, or orchestration logic change. DeepEval also goes beyond just RAG, with support for summarization, conversational flows, and end-to-end evaluation, along with custom judge-based metrics like G-Eval. That broader coverage makes it useful for multi-turn assistants and other LLM surfaces, even if it's less specifically optimized for deep RAG-focused analysis.
RAGAS: research-driven RAG specialization
Instead of treating evaluation like testing, RAGAS leans into a more systematic, research-inspired approach tailored specifically for RAG. The goal is to move teams away from vibe checks and toward structured evaluation loops, with a set of metrics designed around the failure modes that actually show up in RAG pipelines.
You can see that focus clearly in its metrics. RAGAS provides measures for things like faithfulness, response relevancy, context precision, and context recall, each aimed at separating retrieval quality from generation quality. For example, faithfulness checks whether the response is actually supported by the retrieved context, while context precision and recall look at whether the retriever brought back the right information in the first place.
RAGAS gives teams a language that matches how they debug real RAG issues. The tradeoff is that it is more narrowly focused, less flexible than DeepEval for non-RAG use cases, and less integrated into day-to-day workflows compared to LangSmith’s tracing and collaboration features.
LangSmith: observability first for LangChain
Instead of treating evaluation as a standalone step, LangSmith makes it part of a broader platform that brings together tracing, datasets, experiment comparison, and production monitoring. You should be able to understand how your application behaved end-to-end, with the trace acting as the central object that shows what happened at each step. LangChain gets this visibility by automatically capturing each step in your pipeline, including inputs, outputs, intermediate calls, and metadata, and linking them into a single trace that you can inspect.
This observability-first model becomes especially useful for complex RAG and agent workflows, where a single score rarely tells the full story. If a response is poor, you typically want to dig deeper and look at what documents were retrieved, which tools were called, how long each stage took, which prompt version was used, and what the model actually produced along the way. LangSmith makes that easy by linking evaluation directly to traces and datasets. You can quickly go from "this failed" to the exact execution path behind it.
LangSmith tends to work best for teams already using LangChain or LangGraph (even though it aims to be framework agnostic), and its real strength is the unified workflow for debugging, comparing runs, managing datasets, and monitoring live systems. The tradeoff is that if you are looking for something lightweight, code first, or fully open-source, it can feel more platform-heavy than necessary.
A practical test case
In this article, we'll use the same RAG evaluation scenario across all three frameworks (i.e., support question/answering system backed by technical product documentation). The application is designed to answer questions a user might ask about setup steps, configuration options, troubleshooting guidance, feature limitations, and account behavior. In practice, things can break at multiple points. For instance, the retriever may surface incomplete or irrelevant context, the model may misinterpret what was retrieved, or the final response may sound confident while introducing details that were never present in the source material. To capture this, the test evaluates several dimensions of system quality, including the following:
Whether the answer is correct for the question being asked
Whether the retrieved context is actually relevant
Whether the response stays grounded in the provided documents rather than hallucinating unsupported claims
How long the overall pipeline takes to respond
Evaluating all three frameworks
To keep this comparison fair, all three tools evaluate the same tiny RAG Q&A app built with LangChain. For reference, you can find the source code for the sample RAG application on GitHub. In the application, the retriever returns a list of contexts, and the generator produces an answer strictly from those contexts (or refuses with “I don't know”). I also keep the judge model consistent by using JUDGE_MODEL across the scripts. For a comparison like this, the contract is just question, answer, and contexts. In the repo, that’s implemented under src/llm_eval_comparison/rag.py.
DeepEval: unit testing workflow
DeepEval feels closest to a unit testing workflow. You take a model prediction, wrap it in an LLMTestCase, and assert on evaluation metrics, much like you would assert on function outputs in a traditional test. The following code snippet illustrates the core testing loop that uses the LLMTestCase for evaluation (see scripts/eval_deepeval.py for the full script):
from deepeval import assert_test
from deepeval.metrics import AnswerRelevancyMetric, FaithfulnessMetric
from deepeval.test_case import LLMTestCase
# app = build_app(provider="openai")
# judge_model = os.getenv("JUDGE_MODEL", "gpt-5.4")
def test_rag_quality(row):
rec = app.predict(row["question"])
assert_test(
LLMTestCase(
input=row["question"],
actual_output=rec["answer"],
expected_output=row["ground_truth"],
retrieval_context=rec["contexts"],
),
[
AnswerRelevancyMetric(threshold=0.7, model=judge_model),
FaithfulnessMetric(threshold=0.7, model=judge_model),
],
)On this small dataset, DeepEval produced perfect scores:

Where it becomes more useful is when you plug it into CI and run it against a larger, well-curated golden dataset, turning evaluation into a reliable regression check rather than a one-off experiment.
RAGAS: RAG-native metrics over a dataset
Instead of writing test cases, with RAGAS, you start by building a dataset and then run a suite of RAG-specific metrics over it. The workflow is closer to analysis than testing; you’re looking at scores across the dataset to understand where things are breaking down.
The following code snippet illustrates the core logic of RAGAS evaluation (see scripts/eval_ragas.py for the full script):
from ragas import evaluate
from ragas.metrics import answer_relevancy, context_precision, context_recall, faithfulness
# dataset has: question, answer, contexts, ground_truth
# evaluator_llm = ...
# evaluator_embeddings = ...
answer_relevancy.strictness = 1
result = evaluate(
dataset,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall],
llm=evaluator_llm,
embeddings=evaluator_embeddings,
)
print(result)On this run, the aggregate metrics looked like this:
Evaluating: 100%|███████████| 16/16 [00:13<00:00, 1.15it/s]
{'faithfulness': 0.6667, 'answer_relevancy': 0.6047, 'context_precision': 0.8125, 'context_recall': 1.0000}
user_input ... context_recall
0 How do I reset my AcmeCloud password from the ... ... 1.0
1 What is the default API rate limit per key? ... 1.0
2 What is the refund policy for monthly plans? ... 1.0
3 Does AcmeCloud support SAML SSO on the Starter... ... 1.0
[4 rows x 8 columns]Notice that retrieval recall is perfect, which suggests the retriever is finding all the relevant information, but the lower faithfulness and answer relevancy scores indicate that the model is not always using that context correctly. This is exactly where RAGAS shines: it pushes you to think in terms of tradeoffs (coverage vs. noise vs. grounding) and gives you the insights to diagnose where the pipeline is failing.
LangSmith: tracing-first evaluation and experiments
With LangSmith, you can run an experiment, compare it with a previous run, and then drill straight into the trace when something looks wrong. That makes it feel less like a standalone evaluation tool and more like a full debugging and iteration environment for LLM applications.
To evaluate using LangSmith, I created a dataset, ran a target() function that returns answer, contexts, and latency_s, and attached evaluators on top.
The following code snippet illustrates the core logic of LangSmith evaluation (see scripts/eval_langsmith.py for the full script):
import os
from langsmith import Client
from openevals.llm import create_llm_as_judge
client = Client()
judge_model = os.getenv("JUDGE_MODEL", "gpt-5.4")
# dataset_name = "..."
# target = ...
# correctness = ... (e.g., create_llm_as_judge(...))
def groundedness_prompt(*, inputs=None, outputs=None, **_kwargs):
question = (inputs or {}).get("question")
answer = (outputs or {}).get("answer", "")
contexts = (outputs or {}).get("contexts") or []
return [{"role": "user", "content": f\"\"\"\
Grade groundedness. Score 1 if every factual claim is supported by contexts; else 0.
If answer is exactly \"I don't know\", score 1.
Q: {question}
Contexts: {contexts}
Answer: {answer}
\"\"\"}]
groundedness = create_llm_as_judge(
prompt=groundedness_prompt,
model=f"openai:{judge_model}",
feedback_key="groundedness",
)
client.evaluate( # results show up as an experiment in the LangSmith UI
target,
data=dataset_name,
evaluators=[
lambda inputs, outputs, reference_outputs: correctness(inputs=inputs, outputs=outputs, reference_outputs=reference_outputs),
lambda inputs, outputs, reference_outputs: groundedness(inputs=inputs, outputs=outputs, reference_outputs=reference_outputs),
],
)LangSmith emits a web URL with evaluation results that you can open in the browser. You can view the results only if you are logged in to your account, so access is scoped and handled securely.
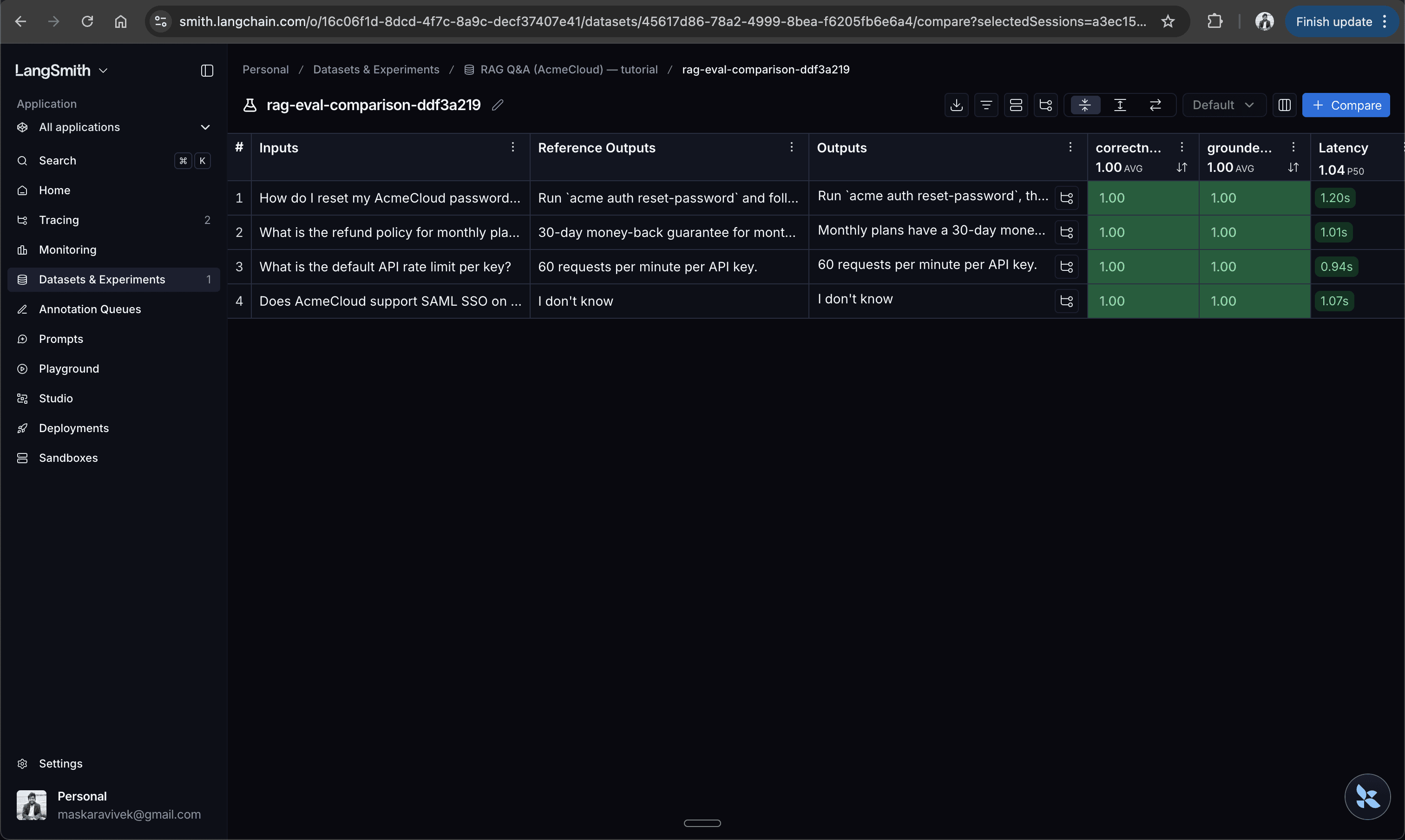
What stands out with LangSmith is how quickly evaluation turns into debugging. When a row scores poorly, you can open the exact trace and inspect the full execution path: the prompt, retrieved documents, intermediate calls, and timing data that led to that result. That tight loop between scoring and inspection is what makes LangSmith especially useful once you move beyond small local experiments and start iterating on real workflows. The table below summarizes the results of the practical evaluation across all three frameworks.
Metrics and interpretability
All three frameworks can tell you when something is wrong, but they differ in what they measure and how easy it is to act on it. At a high level, DeepEval focuses on breadth, RAGAS on RAG-specific depth, and LangSmith on flexible evaluation tied to traces.
DeepEval gives you high-level metrics that you can turn into pass or fail checks, which makes it a natural fit for CI and regression gates. The output is simple and easy to act on, but it does not always tell you where the failure is coming from.
RAGAS takes a more diagnostic approach. Its core metrics, like faithfulness, answer relevancy, context precision, context recall, and map directly to how RAG systems fail. That makes it easier to separate retrieval issues from generation issues and decide what to fix, though it comes with a slightly richer set of signals to interpret.
When compared to DeepEval and RAGAS, LangSmith is less opinionated about metrics themselves. You define evaluators based on what you care about, but the real value comes from how those scores connect to traces. When something fails, you can immediately inspect the full execution path, which makes debugging much faster.
DeepEval gives you simple checks that are easy to enforce, RAGAS gives you deeper RAG-specific diagnostics, and LangSmith gives you flexibility along with strong observability, but less structure out of the box.
Integration and workflow fit
DeepEval behaves like a test framework and fits naturally into CI/CD. RAGAS works better for batch-style evaluation over datasets and tracking metrics over time. LangSmith takes a more platform-oriented approach, combining evaluation with tracing and experiment tracking, especially useful for teams already using LangChain or LangGraph.
The following table compares how these frameworks fit into different workflows:
Feature | DeepEval | RAGAS | LangSmith |
|---|---|---|---|
Primary workflow | Test-driven (CI/CD) | Dataset + metrics analysis | Experiments + tracing |
CI/CD fit | Strong, easy to gate builds | Moderate, not CI-first | Limited, not CI-focused |
Dependencies | Minimal (LLM) | LLM + embeddings | LangSmith platform (+ best with LangChain) |
Best fit | Regression checks | RAG diagnostics | Debugging + production monitoring |
Learning curve and documentation
Out of these three frameworks, DeepEval is generally the easiest to pick up for Python developers because its test-case model feels close to pytest and other familiar testing workflows. RAGAS has a steeper conceptual learning curve, not because the API is necessarily harder, but because its metrics require more care to interpret correctly. LangSmith often has the highest onboarding overhead, since you're learning about a broader workflow built around datasets, experiments, traces, and UI-based analysis.
DeepEval's docs are approachable if you already know what kind of evaluation you want to write. RAGAS's documentation is strongest when explaining the purpose and mechanics of individual RAG metrics. LangSmith's documentation is comprehensive, but it takes longer to absorb because it spans tracing, datasets, experimentation, and production monitoring rather than just evaluation in isolation.
Pricing and scalability considerations
Across all three frameworks, costs typically come from two places: judge model usage (LLM and embedding calls) and any hosted platform you use. Here’s a snapshot as of March 2026:
DeepEval is open source and free to use. Optional hosted platform (Confident AI) with paid tiers starting around $19.99 USD/user/month, that includes 1 GB-month of trace spans, 5,000 online evaluation metric runs per month, and unlimited data retention.
RAGAS is fully open source. In practice, scaling is mostly constrained by your own LLM and embedding usage for the evaluation pipeline.
LangSmith is a hosted platform with a free tier that offers up to 5,000 free traces per month and paid plans starting around $39 USD/seat/month that includes upto 10K traces, with usage-based pricing beyond limits. It also enforces hourly rate limits for trace ingestion that might impact the scale at which you can run your evaluation pipeline.
At scale, the main cost driver is evaluation. Running multiple metrics per example can significantly increase LLM usage, so it’s worth budgeting evaluation traffic separately from production.
When to choose each framework
Each framework is optimized for a different way of working, so the right choice usually depends on your workflow more than the metrics themselves.
DeepEval: If you want a test-driven setup with pytest-style checks, where evaluation acts as a CI gate to catch regressions across prompts, models, and workflows, and you need flexibility beyond just RAG.
RAGAS: If you are focused on improving a RAG pipeline and want metrics that clearly separate retrieval and generation issues, with a dataset-driven workflow that helps you track improvements over time.
LangSmith: If you need evaluation tightly integrated with debugging and production visibility, especially if you are already using LangChain or LangGraph and want a shared workflow for traces, experiments, and datasets.
Here’s a quick side-by-side summary to help you decide which one fits your workflow best:
Category | DeepEval | RAGAS | LangSmith |
|---|---|---|---|
Workflow style | CI-driven, test-first | Dataset + metrics | Experiments + tracing |
RAG metric depth | Medium | High | Medium (customizable) |
Strength | Simple, enforceable checks | Strong RAG diagnostics | Debugging with traces |
Limitation | Limited retrieval insight | Narrower scope | More platform-oriented |
Best for | Regression guardrails | RAG optimization | Production debugging |
In practice, DeepEval is often used as part of the pre-deployment workflow, where changes are gated through automated checks before going live. RAGAS is more commonly used during development and optimization cycles, where teams iterate on retrieval, chunking, and prompting using dataset-level metrics. LangSmith works best in ongoing dev and production workflows, where teams need to debug real runs, compare experiments, and monitor system behavior over time.
Using the right evaluation framework for your context
DeepEval, RAGAS, and LangSmith all tackle the same problem, but in very different ways. DeepEval feels like testing, with clear pass or fail checks you can plug into CI. RAGAS focuses on measurement, with metrics that help you understand where a RAG pipeline is breaking down. LangSmith takes a more workflow-driven approach, combining evaluation with tracing so you can see what actually happened during a run.
The right choice depends on how you work. If you want simple guardrails and a code-first setup, DeepEval is a good fit. If you are focused on improving retrieval and grounding, RAGAS gives you more direct signals. If you need visibility into real runs and a shared workflow for debugging, LangSmith fits better, especially if you are already using LangChain.
In practice, many teams end up using a mix. You might use DeepEval or RAGAS to catch issues before changes go live, and rely on LangSmith to debug problems in production. Starting with what fits your current workflow usually works best, and you can expand from there as your needs grow.
For more developer guides and breakdowns, subscribe to the Descope blog or follow us on LinkedIn, X, and Bluesky.



