


Table of Contents
Don't have the time to read the entire post? Our human writers will be sad, but we understand. Summarize the post with your preferred LLM here instead.
In March 2026, Perplexity CTO Deni Yarats told attending developers that the company was moving away from MCP internally, opting instead for traditional APIs and CLIs (Command-Line Interfaces). A social media post about this declaration went viral and stoked a heated debate, with many declaring MCP “dead.” Within days, the discussion had formed into distinctive camps:
Those who preferred CLI (possibly due to a distaste for MCP)
Those who defended MCP
Those who felt both had their merits in different contexts
It’s worth noting that Perplexity still maintains their public MCP server, and that Yarats’ comments were about internal decisions made to reduce context window overhead from tool schemas and authentication friction at scale. For Perplexity, this was an internal tooling decision driven by specific pain points. But for many jumping into the fray of “MCP vs. CLI,” it was a eulogy for a protocol they disliked.
What the Perplexity comment snowballed into is worth discussing because the underlying tension is real, and we’re unlikely to see a clear winner anytime soon. However, much of the sensationalized rhetoric you’ll see mourning MCP is just that: pure hyperbole. Let’s get into why.
What CLI gets right (that MCP doesn’t)
As mentioned above, Perplexity was internally moving to APIs and CLIs for efficiency gains. This is a case that is both provable and reasonable when comparing MCP and CLI. Benchmarks where both are pitted against the same API tasks found that CLI-based agents can use an order of magnitude fewer tokens for simple operations. In Smithery’s 756-run test across three models and three APIs, CLI agents consistently used fewer tokens per simple operation than their MCP counterparts.
This gap is created almost entirely by schema overhead. A typical MCP server injects its full catalog of tool definitions into the context window (the LLM’s “working memory”) before the agent even does anything useful. For a well-known API like GitHub’s, that catalog alone can be a massive tax on token costs versus the complexity of the actual task.
Token efficiency isn’t the only advantage, though. LLMs have been trained on enormous volumes of shell interactions (e.g., terminal-based text interfaces). That includes scenarios like GitHub repositories, code-heavy tutorials, StackOverflow answers with plenty of code examples, and so on. The result is that models are fluent in CLI patterns in a way they’re not yet fluent in MCP’s JSON-RPC schemas. The cost of speaking in their native tongue, in a sense, is considerably less than one they’ve only recently adopted. Unix philosophy (i.e., piping, chaining, redirecting output) is deeply embedded in model weights (numerical values representing the significance an LLM assigns to a specific input).
MCP calls don’t chain, and there’s no equivalent to that underlying computing philosophy that is, for now, their mother tongue.
For local tools like git, docker, or ffmpeg, CLI is the native state and there’s no need for MCP to replace it. In their testing editorial, Smithery framed it well: The debate of “MCP or CLI” is the wrong fight because these interfaces solve fundamentally different problems. For a single developer automating their own workflow with known/trusted tools, CLI is simpler, cheaper, and pragmatic. Why use MCP there?
That said, token efficiency and task success rates are not the same metric. The Smithery benchmark found that CLI’s interaction overhead (browsing available commands, parsing JSON output, serializing arguments) meant successful CLI runs often consumed more total actions and more billed tokens than the MCP equivalents doing the same task with less tool usage.
Where CLI stops working (and MCP starts)
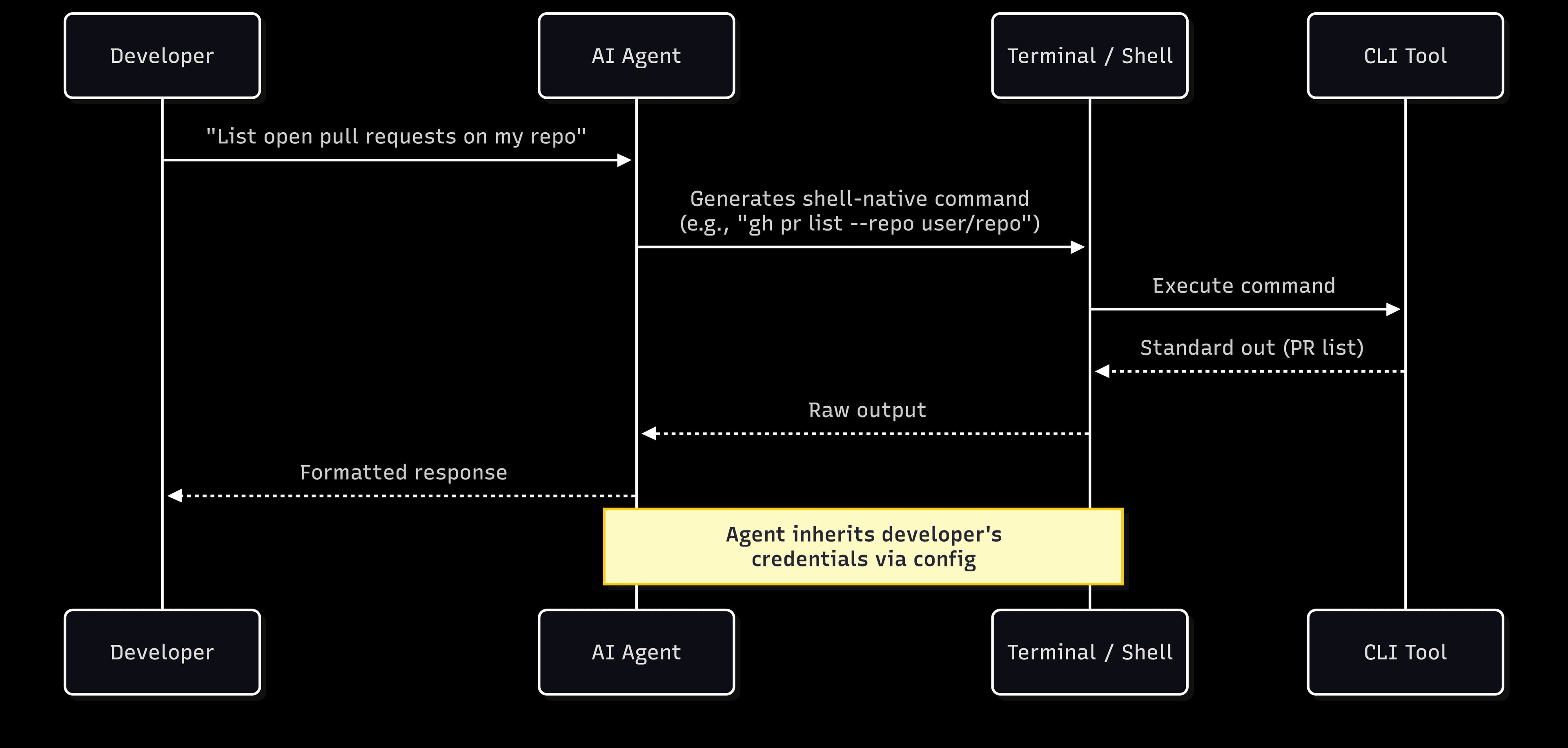
The point where CLI drops the ball arrives the moment the agent stops acting as “you” (who is probably a single developer) and on behalf of someone else (like a customer or end user). If you’re building a product where your agent reads a customer’s repositories, writes to the management tools, or messages their team Slack, you have crossed into a region where CLI’s human-first design (not agent-first) becomes a liability.
In most CLI scenarios, auth isn’t really a priority. Typically, there’s no additional action needed, the CLI agents just inherit the credentials of whoever runs them. That’s great, if you’re a solo dev in your own environment.
You could also authenticate with the `auth login` command, which might take you to a browser to log in via OAuth, perform a device code flow, or leverage API keys stored in configuration files. But that’s far from user or customer-facing territory.
Here’s the issue when you go outside those bounds:
There is no per-user scoping
There is no consent flow asking whether a specific customer wants to authorize a specific action on a specific resource
There is no tenant isolation preventing one customer’s data from leaking into another’s context
There is no structured audit trail recording which agent accessed what, when, and under whose authority
In fairness, MCP doesn’t hand you any of these features for free, either. But it does create the architectural scaffolding for per-user auth, scoped tokens, and auditability. Tenant isolation, prod-ready logging, and consent management are layers you can build on top—easily enough that they’ve become table stakes for enterprise MCP deployments. The key difference here is that MCP was designed with these layers and extensions in mind. CLI is a legacy method that was not.
With CLI, none of the features are components you can simply bolt on after the fact. They’re foundational decisions that determine whether a system can operate in end-customer-facing production at all, especially in regulated or multi-tenant agentic environments.
The problem MCP was actually built to solve
MCP's token overhead is real, and the cost is non-zero. The schema injection is considerable. Take Cloudflare's API spec, for example: it can easily run over a million tokens as raw MCP tool definitions. But this token cost challenge is a solvable engineering problem rather than a fundamental flaw. MCP tool schema does not need to live in the context window for every tool call.
Here’s the solution to an early implementation error with MCP: Cloudflare's Code Mode collapses thousands of endpoints into just two tools, search() and execute(). If the agent writes JavaScript against a typed API instead of loading every schema upfront, token usage drops by over 99%. Anthropic's own code execution pattern takes a similar approach, presenting MCP servers as code APIs with progressive disclosure so agents load only the tool definitions they need for a given task. This effectively cuts context overhead by up to 98.7%.
Besides the schema overhead being a non-issue, MCP solves problems CLI doesn’t attempt to address. That difference in design heavily favors MCP as the scope of agent deployment widens. In the Smithery benchmarks we referenced above, they found that for remote services and unfamiliar APIs, native MCP tool integration consistently gave agents the best chance of completing the task. And, that’s kind of the point of AI agents: to do a task successfully. If an agent fails a task, it doesn’t really matter whether it uses ten tokens or ten million. It still failed.
As seen in the Smithery report, MCP tool schemas reduce the interaction overhead that CLI agents accumulate when discovering, parsing, and serializing as they deal with unfamiliar APIs. With the Code Mode / Code Execution pattern, the context cost drops to nearly zero, giving us a strong answer for why agents should use MCP when interacting with external resources.
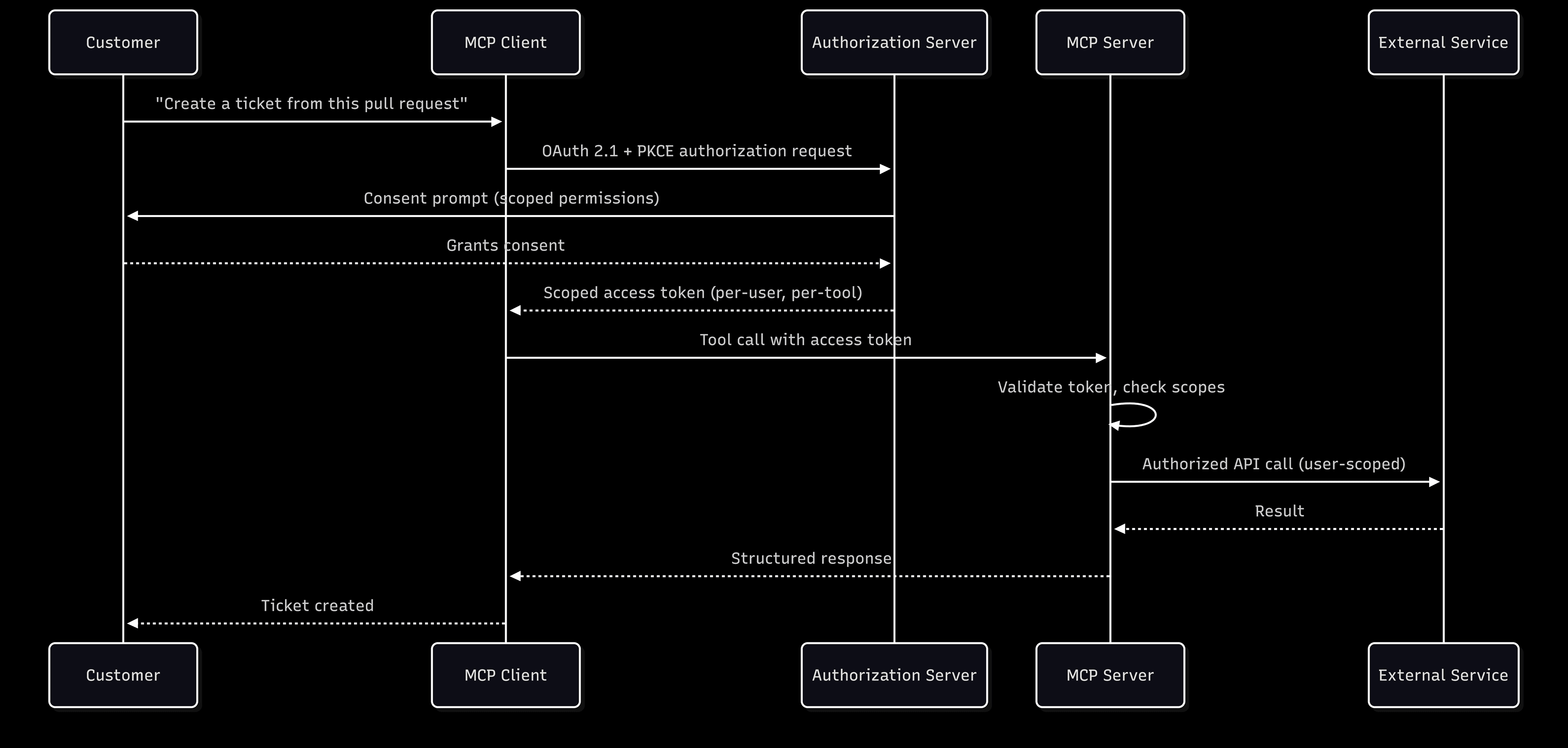
MCP’s authorization specification mandates OAuth 2.1 with PKCE for all clients connecting to remote servers. This means, by default:
Per-user authentication
Scoped access tokens
Consent management
These are all part of the protocol's design rather than bolt-on afterthoughts. Dynamic Client Registration (DCR) or Client ID Metadata Documents (CIMD) allows agents to connect to servers at runtime without manual pre-registration. From what we’ve seen, any system admin that intends to scale agent-to-service connections across an organization has already tossed manual pre-registration out of consideration.
At the tool level, MCP enables granular scoping. A database MCP server can expose separate permissions for read, write, and deletion. This maps directly to the MCP server security best practices many compliance frameworks require. The JSON-RPC transport modality provides the basis for structured audit trails by default, recording interactions in a format that neatly integrates with existing SIEM infrastructure.
Choose based on who the agent works for
The decision here isn’t really “which is better” but “who is the agent acting for.” Ask yourself, what is the agent’s relationship to the person whose data it touches?
When the agent acts as the developer, especially solo devs, CLI’s efficiency advantage is demonstrable and its security model is mostly adequate. The attack surface is limited to the developer themselves.
When the agent acts on behalf of other people (customers, employees, partners) or interacts with other resources on its own, the security model becomes the point of leverage. When you’re serious about production, per-user auth, scopes, consent, tenant isolation, and logging are the minimum requirements for any environment where compliance matters. Nearly every B2B context and an increasing number of consumer ones fits this description.
The pattern we’re likely to see mature out of this debate is a hybrid approach: CLI for local tools and dev flows; MCP for remote services, internal APIs, and multi-tenant scenarios. Essentially, with any workflow where the agent’s behavior can impact anyone other than the person who built it, you should look at MCP.
Smithery’s conclusion from their benchmark echoes this sentiment: prefer CLI for local tools, MCP integrations for remote services and security-sensitive workflows. Start by building a good API first with good documentation, then expose an MCP adapter on top.
Identity is the underlying challenge
What remains constant across both CLI and MCP is the need for identity infrastructure when agents interact with external systems on their users’ behalf.
The MCP spec codifies much of what production deployments need: OAuth 2.1 with PKCE, client registration (DCR/CIMD), scoped access tokens. CLI leaves those requirements as exercises from the implementer. But in either case, the underlying imperative is the same: an identity provider that treats AI agents and MCP servers and first-class identities alongside human users, not as an afterthought bolted onto an existing IAM stack. Descope’s Agentic Identity Hub provides all the tools and resources MCP server developers need to add protocol-compliant OAuth, user consent, and per-tool scoping without implementing the auth spec from scratch. No expertise or code base refactoring required.
With Descope, AI agent builders can issue short-lived, scoped credentials for downstream service connections without managing token storage or refresh cycles themselves. Security teams get policy-based governance, audit trails, and lifecycle management across the entire agent and MCP surface.
The protocol debate may continue to shift, but the identity layer underneath doesn’t have to be the hard part. Get started with a Free Forever Descope Account, reach out to our team of auth experts, or connect with like-minded builders in our developer community, AuthTown.



