


Table of Contents
Don't have the time to read the entire post? Our human writers will be sad, but we understand. Summarize the post with your preferred LLM here instead.
The Model Context Protocol (MCP) has had a profound impact on the AI ecosystem within its first year. First introduced by Anthropic in late 2024, MCP has grown rapidly: publication of thousands of servers, adoption from tech giants (Microsoft, Google, OpenAI), and stewardship by the Linux Foundation.
The spec and its auth guidelines have both seen multiple major revisions during its brief lifetime. It’s these characteristics (ecosystem, adoption, velocity) that make MCP so exciting. But they’re also what make it a potential risk.
This guide examines the MCP server security best practices that matter most for production deployments today, along with the context you need to understand why each one can make a difference.
MCP security risks
Developers are deploying MCP servers faster than traditional security practices can keep up. Case in point: Knostic researchers scanned nearly 2,000 publicly accessible MCP servers and found that every single verified instance granted access to internal tool listings without any authentication. In a similar disclosure, Backslash Security identified another pool of servers bound to all interfaces (0.0.0.0), many configured in ways that would allow arbitrary code execution.
This fast-moving protocol has many inexperienced (i.e., “vibe”) coders deploying servers with virtually zero protections or reckless (default) configurations. For example, overscoping is one of the most pervasive risks across all published MCP servers today. Backslash Security’s Trupti Shiralkar described the issue in her address at the Descope Global MCP Hackathon: “I found that by default, MCP servers could have a lot of excessive permissions.” With excessive permissions, said Shiralkar, “bad actors can execute OS command injection” and “path traversal vulnerabilities where they eventually get to sensitive information.”
Similarly, security researcher and Databricks engineer Andre Landgraf demonstrated in a live session that prompt injection attacks can bypass model-level defenses with ease. Models Landgraf tested returned sensitive admin API keys when an injected instruction asked for them. As Landgraf put it, in-model defenses “cannot be the foundation on which you build your security architecture.”
Yet, instead of asking the right questions about MCP (e.g., “is my server secure, and how do I know it will stay secure?”), many devs are all too ready to publish projects with minimal security.
The good news is that the MCP specification has been getting clearer and more prescriptive about security with every revision. The challenge, however, is implementation: the spec recommends OAuth 2.1, PKCE, Protected Resource Metadata, and client registration mechanisms that need meaningful identity expertise to get right. Most dev teams don’t have that experience, and most aren’t actively trying to acquire it—but, fortunately, that’s beginning to change as awareness of the risks spreads.
Below are the top eight MCP server security best practices that we recommend for developing resilient, production-ready AI projects.
1. Separate your authorization server from your resource server
The MCP spec is explicit about this today, but it was not always the case. Earlier versions of the auth specification treat MCP servers as both resource servers and authorization servers simultaneously, which created significant complexity for implementers. The June 2025 spec revision formalized the separation: now MCP servers are officially classified as OAuth Resource Servers, and the authorization function belongs to a dedicated authorization server.
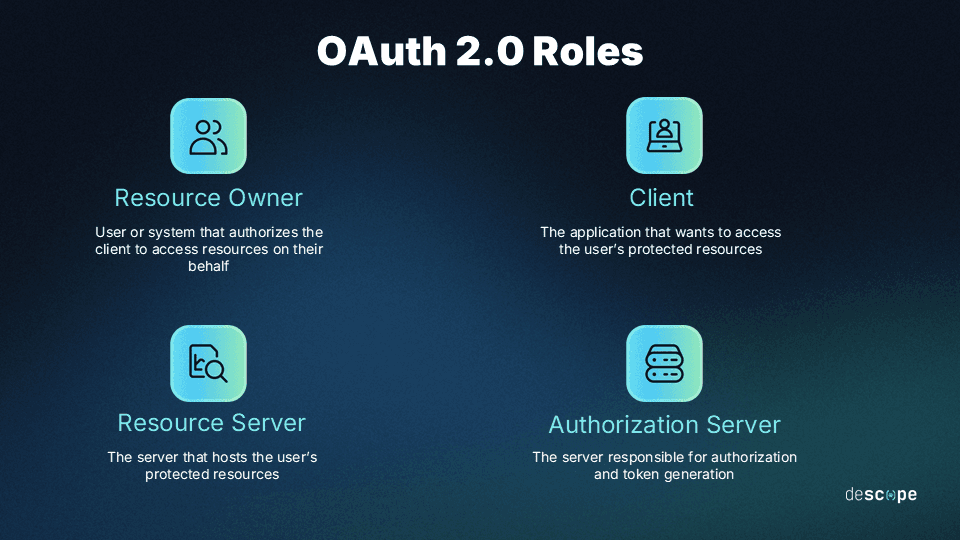
When we dug into the MCP authorization specification earlier last year, this was one of the easiest architectural recommendations to make: keep these roles separated. The authorization server handles user auth, token issuance, and client registration. The resource server (your MCP server) validates tokens and enforces access controls. Conflating these two roles means maintaining OAuth infrastructure alongside your application logic, which makes auditing painful, harder to scale, and likely to drift out of compliance as the auth spec evolves.
See our MCP Authorization Specification deep dive to learn more.
The cleaner (and now mandated) architecture delegates authorization to a dedicated identity provider (IdP) and lets your MCP server stick to what it’s actually built to do. In the best practice scenario, your MCP server publishes a .well-known endpoint via Protected Resource Metadata (RFC 9728) that tells clients where to find the authorization server. Clients handle discovery automatically, and you don’t have to hardcode anything.
2. Implement OAuth 2.1 and PKCE properly
For HTTP-based MCP support, OAuth 2.1 is not optional. It is the standard mandated by the current auth spec, and PKCE (Proof Key for Code Exchange) has been a requirement for all public clients since day one. This covers most MCP clients in the wild: CLI tools, IDE extensions, desktop applications, etc. Since most MCP clients cannot securely store a client secret, PKCE is the mechanism that secures the authorization code flow against interception.
The problem, however, is that implementing OAuth 2.1 correctly is harder than it sounds on paper. Even if you’re familiar with OAuth, its still in-revision update deprecates many methods and adds several more. Each of these details matters, especially for securing an MCP server. For example, Resource Indicators (RFC 8707) must be used to bind specific tokens to specific MCP servers, preventing tokens issued for one server from being used against another.
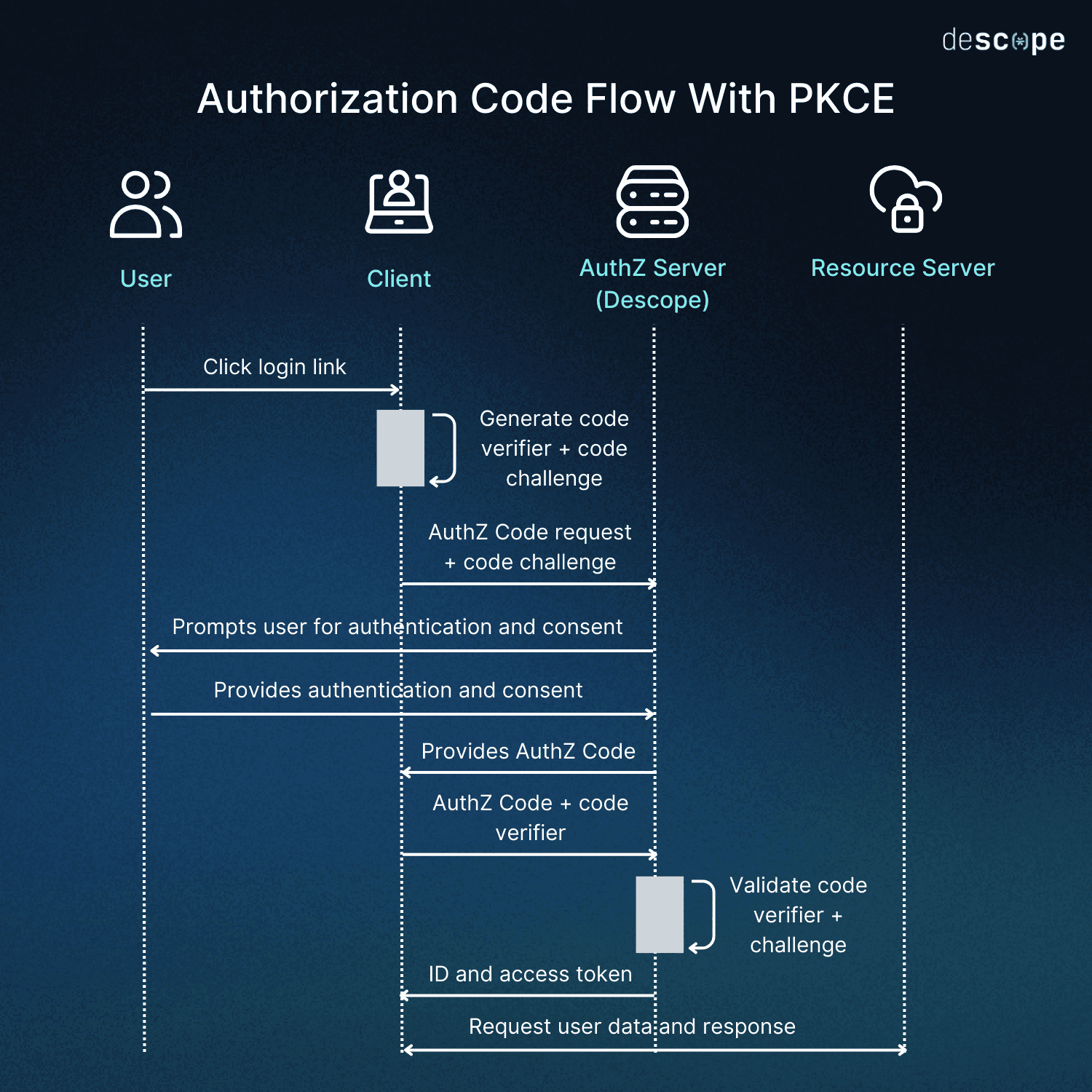
Learn more about OAuth 2.1 vs. OAuth 2.0 and how PKCE works.
If your team is not deeply familiar with OAuth and its latest in-draft iteration, either take the time to learn the spec or seek a solution that follows it to the letter. The cost of getting it wrong is higher than the cost of following a well-established foundation, even if it takes a little longer to understand. The OWASP GenAI Security Project’s guide for secure MCP server development echoes this conclusion, listing OAuth 2.1 / OpenID Connect enforcement as the first item needed to pass its minimum security bar.
3. Protect your server with user auth and SSO
For enterprise-facing MCP servers, connecting to your existing identity infrastructure is essential for getting production-ready. Users should authenticate through your SSO layer before any agent takes action on their behalf, whether that’s connecting with a shared Google Drive or connecting to your GitHub organization. Your MCP server must validate that the token it receives corresponds to a real authenticated user with the appropriate permissions for what is being requested.
This matters in large part because relying on the underlying language model to police access may be tempting to novice devs, but it’s ultimately quite dangerous. Prompt injection, context poisoning, and instruction drift are problems that carry architectural impact, and the only reliable fix is proper authentication, authorization, and scoping at the infrastructure level.
The OWASP guide for MCP server development once again iterates this as an explicit recommendation: centralize policy enforcement in a dedicated auth layer rather than relying on a model with blanket permissions to distinguish between legitimate instructions and malicious ones.
Learn more about why MCP servers need user auth in Why Model-Level Defenses Are Not Enough for MCP and the Top 6 MCP Vulnerabilities.
4. Build consent management into the flow
Consent is a challenge closely related to user auth, though it’s not quite as straightforward for a couple of reasons. First, most applications assume that users interact with the system directly (though this is changing, slowly, like with the Agent Payments Protocol).
MCP breaks that expectation, doing away with the typical “hands on keyboard” scenario. When a user connects a semi-autonomous AI agent to your MCP server, the agent acts on the user’s behalf, but it is the one making requests. Because of this, we’re dealt the second part of this challenge: the user may have limited visibility into what the agent is doing, what data it is accessing, or what actions it is taking.
Consent management is how you restore that visibility and control. Before an MCP client can act, users should see a clear consent screen that describes what is being requested: which tools are accessible, what data may be read or written, and for how long.
Time-bound consent is particularly important (i.e., short-lived tokens). A user authorizing an agent to draft a proposal in Google Docs does not necessarily want to grant that agent indefinite access to all their Google apps (email, calendar, etc.). Consent should be scoped to the task and expire after the task is done.
5. Enforce scope-based access control at the tool level
We’ve mentioned avoiding overscoping a few times already, but the principle that underlies this (least-privilege) is already well-established in traditional identity scenarios. However, in an MCP server with multiple tools, those enforcing this can become much more complex.
Picture this: An enterprise uses an agent to help employees across several services connected with the organization: calendar, email, a CRM, and an internal API. Each of those environments carries different risks, and they each have different permissions associated with different actions. An agent that can read calendar events should not automatically be able to write CRM records.
The OWASP GenAI Security Project flags the same pattern as a top vulnerability, noting that over-privileged tools or board access permissions amplify the impact of any single breach. They recommend that policy enforcement should be centralized so access decisions remain consistent across every agent, server, and tool in your environment.
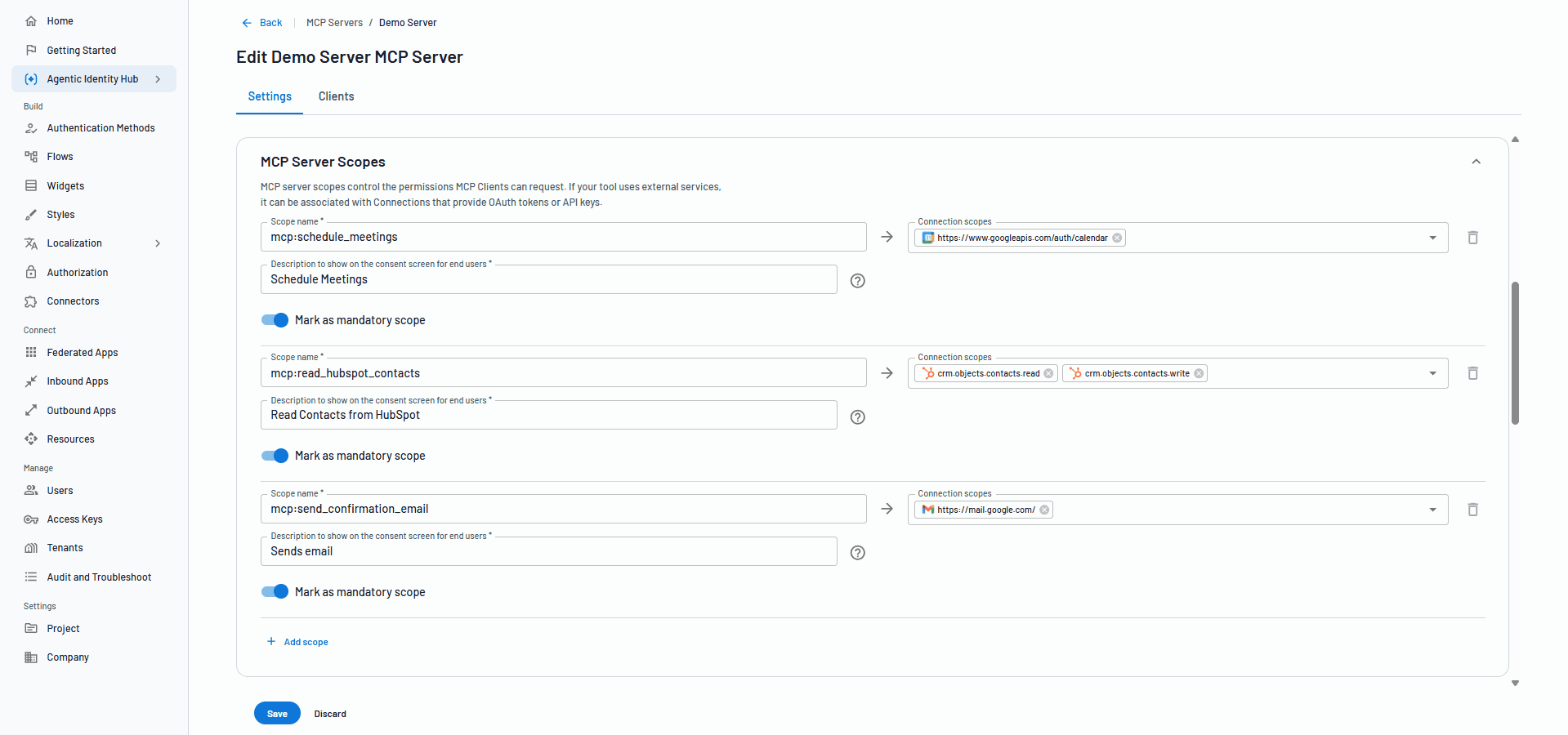
Progressive scoping takes this a step further. Rather than requesting all permissions up front, agents should request only the scopes needed for the current task. If a new task requires additional access mid-session, the agent can request the additional needed scopes incrementally. This approach minimizes token vulnerability, reduces the attack surface generated by any given interaction, and makes it easier to audit what each agent actually accessed during a session.
Take a deeper dive into how progressive scoping works in Securing Your APIs With Progressive Scoping.
6. Support all three MCP client registration methods
One of the more significant shifts in the MCP spec revision was in preferred client registration methods. The spec now designates Client ID Metadata Documents (CIMD) as the default (SHOULD) for client registration, while Dynamic Client Registration (DCR) is listed as optional (MAY).
Understanding why this shift occurred requires knowledge of the underlying problem DCR sought to solve, and where it fell short.
DCR was the early default because MCP needed a way for unknown clients to register dynamically at runtime, without manual pre-registration for every possible agent. DCR solved that by letting clients register themselves via an open /register endpoint. It worked, but it created a standing set of security risks: anyone could POST to a registration endpoint, client identities can be spoofed (an attacker can register the same client_name as a trusted app), and (at scale) authorization server databases fill up with countless stale entries that may never be cleaned up.
Hardening DCR is possible, and for certain environments is still the right call. Controlled deployments with known, long-lived clients are a reasonable fit. If you are already using or plan to use DCR for this reason, you’ll still want to pursue layered verification, IP validation, scope whitelisting, and short-lived credentials to protect against abuse. Our DCR hardening guide covers these practices in more detail.
CIMD takes a fundamentally different approach. Instead of registering via an endpoint, the client_id is a stable HTTPS URL pointing to a JSON metadata document the client hosts. The authorization server fetches that document at runtime, validates it, and caches it (i.e., stores temporarily).
There is no registration endpoint to abuse, and client identity is tied to domain ownership rather than simply being open. One verifiable URL represents the entire application, so a single VS Code extension can be recognized across thousands of developer instances without flooding the authorization server with redundant records.
Pre-registration remains a valid approach for curated, static setups where you control both sides of the connection. But the greatest potential of MCP lies in its remote application, and pre-registration can’t resolve scenarios with previously unknown clients.
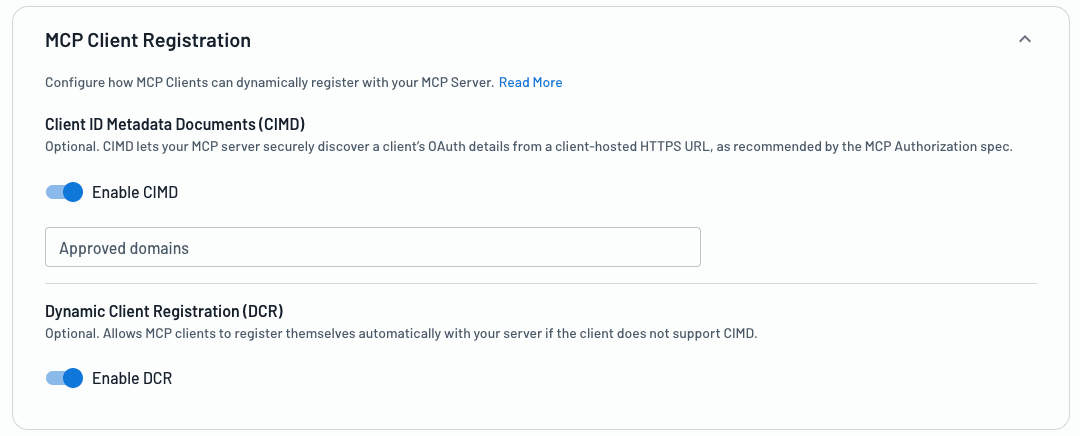
For production deployments today, the best approach is to support all three methods as they relate to your use case, letting the client decide which path to use. This is quickly becoming the standard for identity providers integrating MCP support. The agentic identity capabilities in Descope's console, for example, allow you to enable both DCR and CIMD at the same time. The MCP client decides how to proceed.
For an in-depth discussion of which scenarios are best suited for DCR or CIMD, see DCR vs. CIMD.
7. Store downstream credentials securely
MCP servers frequently need to call third-party services on behalf of users: APIs, databases, SaaS tools, and even other MCP servers or agents. Each of those connections requires credentials, and how those credentials are stored and managed is a vital security decision. If it’s not a choice you’re making intentionally, it’s left to an insecure default.
The dominant pattern in the wild today is storing credentials as static API keys or Personal Access Tokens (PATs) in environment variables. It is simple and it works, but static secrets are long-lived, hard to rotate, and a single point of failure if a server is compromised. Recent analysis of more than 5,000 open-source MCP servers revealed that over half relied on this approach, while only a small fraction used OAuth for downstream connections.
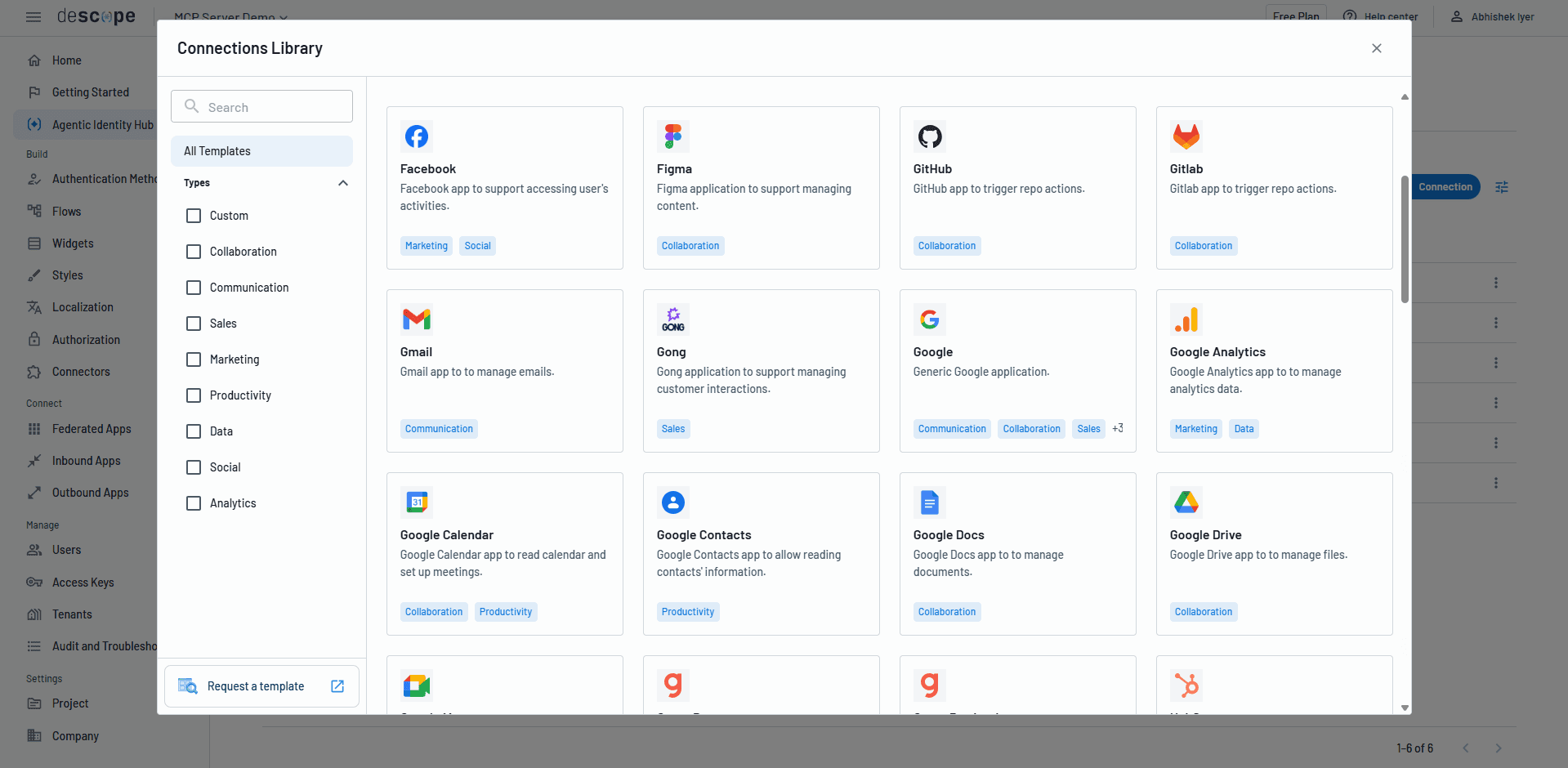
The better and more secure approach is a dedicated credential vault, purpose-built for agent connections: short-lived tokens scoped to specific services, automatic rotation, and per-service access controls. This limits the impact of any single credential being compromised and keeps the token lifecycle manageable as the number of downstream connections grows. The OWASP best practices are clear on this point: store secrets in credential vaults, never in environment variables or logs, and the LLM should never have access to them at all.
Learn why OAuth is the preferred approach for agentic scenarios in OAuth vs. API Keys for Agentic AI.
8. Audit everything
An MCP server that cannot tell you who connected, what they did, and why they had access to do it is not production ready. Not for user-facing scenarios, and definitely not for enterprise.
Each MCP client should carry a dedicated identity tied to the user it is acting on behalf of, with observable attributes including registration method, IP address, client type, and the scopes that were granted. Every significant event in the client lifecycle should generate an auditable log entry: consent granted and for how long, tokens issued and when they expired, scope changes, anomalous activity, and revocations.
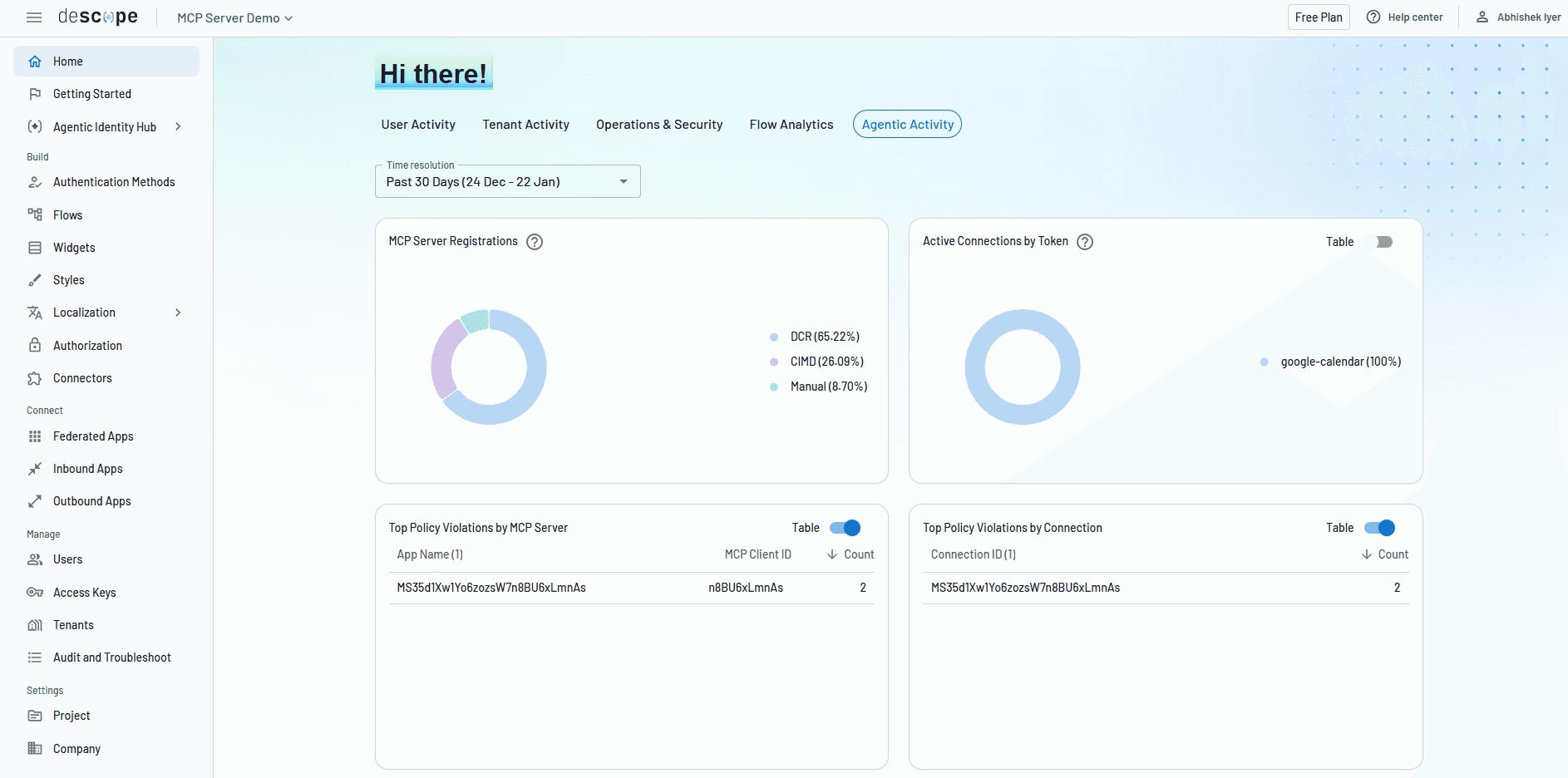
For example, Descope allows devs and organizations to audit agentic identities, monitoring their behavior through four key stages:
Registration: Agent creation and introduction, when it requests permissions and identifies itself.
Consent: A user or admin grants scopes to approve what the agent is allowed to do on their behalf.
Connectivity: Agent carries out its tasks by connecting to external systems.
Termination: The agent’s credentials must be revoked and its access retired when its task is complete.
OWASP frames this under non-human identity (NHI) governance, treating every automated agent and MCP server system as a first-class identity with unique credentials and tightly scoped permissions. The headline is simple here: if you cannot audit what an NHI did and revoke its access on demand, you do not actually control it.
But these aren’t limited to benefitting your security posture alone; this is also a boon to operational visibility. When an agent does something unexpected, audit logs are how you understand what happened. When a credential is compromised, logs are how you contain the damage. But logs are also how you troubleshoot auth issues, which can be difficult to debug without visibility.
Simplifying MCP server security
MCP security is not a solved problem, and so long as it continues to evolve at a breakneck pace, it likely won’t be for a while. The spec is still being revised, attack vectors are still being discovered, and most deployed servers are not yet operating at the standard recommended by this guide. But the practices we’ve outlined here reflect where the security community has arrived at unambiguous conclusions. More importantly, they’re achievable right now.
For teams that do not want to build OAuth infrastructure from scratch, the Descope Agentic Identity Hub provides the auth and access control layer for both internal and external-facing MCP servers. Descope handles OAuth 2.1, PKCE, DCR, CIMD, scope enforcement, consent management, token storage, audit logging, and client lifecycle management out of the box.
WisdomAI used Descope to go from concept to production-ready MCP auth in roughly a day and half, freeing their engineering team to focus on their core capabilities. Daylight Security implementing B2B SSO and customer-facing MCP auth simultaneously, with role-based access controls mapping cleanly across both use cases.
If you’re building or securing an MCP server, start with a free Descope account or book time with our team now. Not sure where to begin? See examples of our MCP and agentic identity capabilities in action at descope.ai, or join our dev community, AuthTown, to connect with real Descopers and like-minded builders.



