

Table of Contents
Workload identity federation is an established implementation pattern in cloud infrastructure. Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure each provide mechanisms for software workloads to authenticate across trust boundaries using short-lived OpenID Connect (OIDC) tokens instead of stored secrets. For standard CI/CD pipelines, Kubernetes pods, and serverless functions, the problem of sprawling and static stored credentials is largely solved.
AI agents introduce a new dynamic to address. Agents call tools, act on behalf of users, and traverse trust boundaries in non-deterministic ways. Because of this dynamism, they need scoped credentials at the moment of invocation, per-workload audit trails, and policy enforcement that accounts for who the agent represents. Static API keys and service accounts don’t provide any of this functionality by default.
This post discusses what workload identity federation is, where standard implementations hit their limit, and how WIF applies to AI agents in dynamic scenarios.
What is workload identity federation?
Workload identity federation (WIF) is a mechanism that lets a workload prove its identity in one environment and receive credentials in another. This is achieved through OIDC tokens rather than the default long-lived secrets. The workload’s native platform (e.g., AWS Security Token Service) issues an OIDC token, which the workload presents to a target system (e.g., GitHub), and receives a short-lived, scoped credential in return.
The target system accepts the token because a trust relationship has been established in advance. This is a configuration that specifies which issuers are trusted, which claims must be validated, and what permissions the subsequent credential should hold. The exchange itself uses either the JWT Bearer grant type defined in RFC 7523 or the token exchange protocol defined in RFC 8693.
WIF aims to replace the risky practice of provisioning a static credential (e.g., an API key) and distributing it to the workload at deployment time. That leads to credential sprawl, an antipattern that GitGuardian research reveals has ballooned since the advent of coding agents. Leaked secrets grew by 151% since 2021, with Claude Code-assisted commits leaking secrets at twice the base rate.
Credential sprawl, when combined with the overhead of rotating these secrets (and the difficulty of detecting a leak in the first place), can lead to a significant and persistent blast radius. Workload credentials are often held by non-human identities and given overly broad permissions, with no expiration or clear ownership. The same credential could be duplicated, appearing in public-facing repositories and waiting to be scanned by a determined threat actor.
WIF resolves this by eliminating the secret entirely. The workload’s proof of identity is its runtime context: its cloud account, Kubernetes namespace, all verified cryptographically by the platform that runs it. Both the JWT Bearer grant type and OAuth Token Exchange are well-established, and the identity format that underlies many workload identity systems (SPIFFE) has proven reliable at scale.
Why is traditional WIF a poor fit for AI agents?
Cloud providers have battle-tested workload identity federation implementations within their own ecosystems:
Google Cloud’s Workload Identity Federation handles federation from external OIDC and SAML issuers into GCP IAM
AWS IAM Identity Providers and STS role assumption do the same thing for AWS resources
Azure Entra supports federated credentials on managed identities and app registrations through Microsoft Entra Workload ID
These implementations handle infrastructure workloads effectively. It’s well-trodden territory: a GitHub Actions runner that pushes code to an AWS S3 bucket, a Google Kubernetes Engine (GKE) pod that reads from Cloud Storage, workloads running on Azure compute platforms using app identities. The trust relationship is simply connecting the cloud provider itself, the target resources, and a policy model that maps to existing roles and permissions.
AI agents don’t really fit into this equation neatly. An agent that authenticates to your identity platform, calls your APIs, and then needs credentials for multiple downstream services (Salesforce, GitHub, Slack) is crossing many trust domains in a single chain of actions. Cloud-native WIF can resolve the first hop, where the agent proves it runs in your infrastructure. But it doesn’t address what happens after that.
How does the agent get a scoped credential for your identity layer? How does that credential properly gate access to downstream services, carrying all the necessary permissions? And how does each step beyond the first trace back to the originating (delegating) user or workload?
Why do AI agents need workload identity federation?
Non-human identities (NHIs) and agentic identities share many characteristics, but their credential requirements differ greatly. This shifts the ways in which agentic identities are best managed when federating workloads, beyond the capabilities of standard infrastructure.
Dynamic tool access
Static machine identities will run the same job in the same way, every single time; agents are dynamic, crossing multiple trust domains in an unprecedented pattern as a matter of course. Instead of calling fixed endpoints defined at build time, agents discover and call tools at runtime. Each one might require different credentials and scopes, but pre-provisioning static credentials for every tool an agent might call is nothing short of impractical. Overpermissioning those credentials sidesteps this, but creates the exact problem WIF is meant to eliminate.
Delegated authority
Agents frequently act on behalf of a human user. The credentials an agent uses downstream need to reflect both the agent’s own identity and the user’s authorized permissions. A static API key doesn’t represent either of these. Workload identity federation gives an agent a verifiable identity at the platform level, and the platform can then evaluate policy against both the agent’s claims and the user’s permissions when issuing downstream credentials.
Ephemeral, high-volume execution
In organizations with entire fleets, agents quickly spin up to execute a task, then terminate. The lifecycle of an agent within a containerized or serverless environment can be mere seconds, which means the credentials they hold should also exist only briefly. Provisioning, rotating, and revoking static credentials at this speed is untenable, but with WIF, the credential only exists for the duration of the token. It’s issued freshly on execution, dies with the task, and leaves no secret lifecycle to manage.
Cross-boundary operation
An agent running your AWS account may need to authenticate to your identity platform, retrieve user context, call an external API on their behalf, and log the entire event chain back to an audit log. Each of these boundary crossings is a trust relationship being checked and exercised. WIF provides the mechanism for the first leg of the journey, but there needs to be an identity layer to handle wherever the agent decides to go next.
What are cloud-native agent identity services?
Taken at their baseline functionality, the cloud platforms offered as examples in this post (AWS, GCP, Azure) illustrate the need for an agent-aware form of WIF. Each of these providers has recognized this gap and responded with dedicated solutions:
AWS launched Amazon Bedrock AgentCore Identity
Microsoft shipped Entra Agent ID
Google introduced Vertex AI Agent Engine
All three of these go beyond the fundamentals of WIF to address credential brokering, user-delegated authority, and per-agent identity records. Where basic WIF only handles the first step for dynamic agents, these newer services cover the whole lifecycle within their own ecosystems. But that is also their chief constraint: each is tightly coupled to the provider. Non-AWS agents can register but still need AWS credentials to participate in AgentCore; similar limitations apply to Azure and GCP.
While these identity services resolve many of the challenges with WIF in agentic contexts, there can be trade-offs for organizations running agents across multiple clouds. Those building on framework-agnostic infrastructure, or needing an identity layer that works independently of the cloud their agents happen to run in, may struggle to unify their identity surface.
How does workload identity federation work for agents?
The exchange follows roughly the same pattern as standard WIF, with extension and adaptation for the agentic context.
The agent runs in a cloud environment with a platform identity attached (an IAM role in AWS, for example).
The agent requests an OIDC token from its cloud provider. On AWS EKS, for example, this token is projected into the pod via IAM Roles for Service Accounts (IRSA).
The agent presents this token to the identity platform’s token endpoint using the JWT Bearer grant type.
The Identity platform validates the token against the issuer’s JWKS endpoint, verifies the claims (issuer, audience, service account, namespace, etc.).
On successful verification, the identity platform issues a scoped access token
The agent uses this platform-issued token to access protected resources (APIs, MCP servers, downstream services).
What makes this distinct from basic WIF is what happens during validation and issuance. An identity platform or service designed for agentic workloads doesn’t simply validate the token and return a generic credential; it creates an identity record for the agent in a directory. The workload’s claims are associated with this record, and all of these characteristics are considered against access policy.
Beyond these steps and differences in methodology, agent-aware identity service’s record also produces audit trails that persist beyond the token’s lifetime. The token may expire, but the record associated with an agent workload remains visible and traceable.
What does workload identity federation look like in practice?
Using the Descope as an example, the Agentic Identity Hub uses the JWT Bearer grant type to exchange cloud OIDC tokens for Descope access tokens. Descope supports tokens from AWS, GCP, and Azure, with each provider needing slightly different steps to set up.
The steps below outline the general pattern that applies to all agentic WIF token exchanges with Descope.
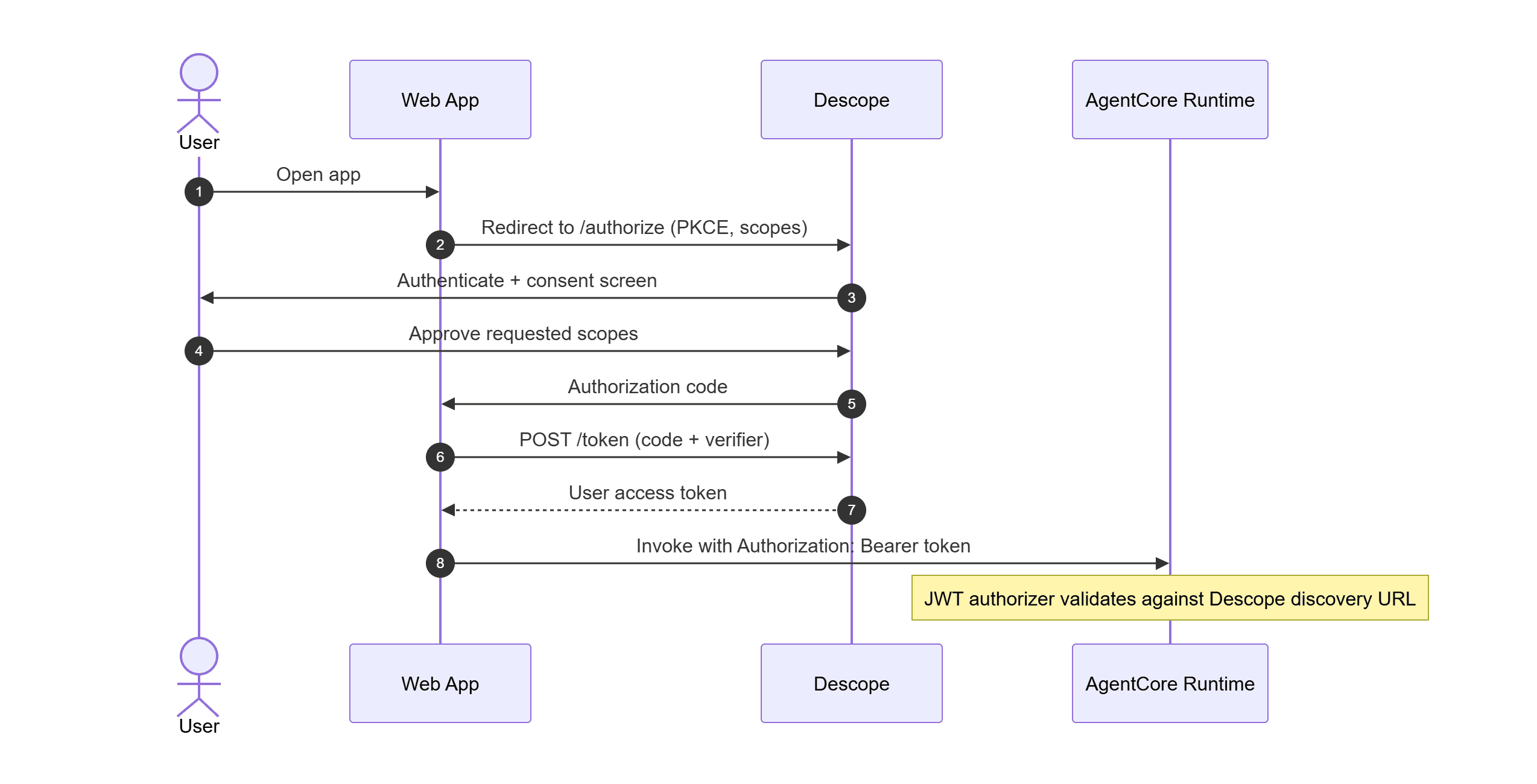
Configuration: You create a client in Descope with the JWT Bearer grant type enabled. You add your cloud provider (with some requiring a handful of steps on their side) as a trusted issuer.
Token exchange: The agent fetches its cloud OIDC token and sends it to Descope’s token endpoint with the JWT Bearer grant type.
Validation: Descope validates incoming tokens against the issuer’s signing keys and verifies the audience claim (
aud) against the configured client ID, then returns a scoped access token.Agentic identity: Each workload that exchanges a token receives an agentic identity record. The record carries the workload’s claims as context for policy evaluation and auditing. Workloads sharing the same client ID but running in different environments still produce distinct identities, so access can be revoked per-deployment without affecting others.
Downstream credential brokering: Once the agent holds a Descope token, it can use Connections to retrieve credentials for downstream services via OAuth Token Exchange. Policies filter scopes at exchange time, evaluated against the agent identity, the originating user’s roles, and tenant context.
Throughout this process, the agent never holds any long-lived credentials for any downstream service. The agent federates into Descope without a stored secret, receives a scoped identity, and brokers out to downstream services through the same platform. Policy enforcement occurs at every step, and audit logging records every action.
Minimizing credential risks with agentic workload federation
Workload identity federation is a well-established practice for infrastructure workloads, and major cloud providers have extended their standard offerings with agent-specific identity services. These are welcome additions for security-minded organizations looking to avoid credential leakage, with the added benefits of per-agent identity records and user-delegated authority. Cloud-specific agent identity services can be a good fit for organizations whose agents live entirely in one cloud.
For organizations building across clouds, agent frameworks, or with infrastructure where human and agent identities need to coexist in the same policy environment, these platform-scoped services could present significant scaling challenges. Descope’s Agentic Identity Hub serves as a cloud-neutral identity layer that unites agents on Azure AI Foundry, Vertex AI, AgentCore, and standalone deployments. They all register in the same directory, with one credential vault, policy engine, and cohesive audit trails regardless of where the agent runs. Instead of a cloud-bounded API, Descope’s integration point with any runtime is a standard OIDC discovery URL.
For a detailed walkthrough of how Descope bridges the gap between each of these ecosystem-locked agent identity services, see the guides on Vertex AI, Azure AI Foundry, and Amazon AgentCore. To get started with workload identity federation in Descope, sign up for a Free Forever Account, join the AuthTown dev community, and dive into the WIF docs to learn more.



