

Table of Contents
Don't have the time to read the entire post? Our human writers will be sad, but we understand. Summarize the post with your preferred LLM here instead.
Virtually every application has resources that need protecting and users who need to access them. Access control is the practice of deciding which users can reach which resources and what they can do when they get there.
Access control picks up where authentication leaves off, just after a user enters the digital doorway. While authentication confirms identity (i.e., “Is the user who they claim to be?”), access control determines and enforces permissions: what should this user be allowed to access and do? A system built with strong authentication but weak access control still leaves sensitive data and actions exposed to anyone who can clear the login screen.
Threat actors who gain initial access move laterally through an organization, looking for ways to elevate their illegitimate permissions through exploits like confused deputy scenarios. With the adoption of agentic AI, access control has become even more fundamental for security posture. IBM’s 2025 Cost of a Data Breach Report found that 97% of AI-related breaches occurred in organizations that lacked proper access controls.
The access control models in this guide offer different approaches to structuring and enforcing permissions. They vary in complexity, granularity, and the assumptions they make about how organizations and users interact with resources. Many production environments use more than one.
How access control began (and evolved)
The foundational problem that access control solves has been around since the very earliest multi-user systems: different users need different levels of access to different resources, and something has to enforce that separation.
Initial approaches were flat by design, blunt instruments built for a now-defunct era of computing.
Discretionary access control (DAC) let resource owners decide who else could access resources, which was flexible but depended entirely on individual judgment; DAC can operate through owner-managed access lists or through transferable capability tokens that don't depend on a single owner.
Mandatory access control (MAC) went the opposite direction, imposing classification-based restrictions from a central authority that no individual user could override. It's rigid by design, though it can co-exist with role-based architecture.
Both approaches were products of their time, suited for rigid environments where the user base was relatively small and the resources being protected were well-defined. Neither DAC nor MAC maps well onto how modern applications manage users, tenants, or resources at scale.
What came after, and what the rest of this guide covers, was a progression toward models that could enforce more nuanced access policies without requiring either total user discretion or total central rigidity.
| DAC / MAC | RBAC | FGA (ReBAC / ABAC) |
|---|---|---|---|
Core approach | Owner discretion (DAC) or central classification (MAC) | Permissions assigned to roles, roles assigned to users | Permissions based on relationships, attributes, or both |
Granularity | Coarse | Coarse to moderate | Fine |
Flexibility | DAC is high but inconsistent; MAC is rigid by design | Moderate, with well-defined roles | High, with dynamic evaluation |
Primary limitation | Doesn’t scale to modern use cases, multi-tenant applications | Role explosion at scale | Higher upfront complexity |
Modern compatibility | Largely sunsetted; however, concepts persist in OS-level controls | Industry default, widely adopted across many verticals | Growing adoption for complex or collaborative environments |
Access control vs. authorization
You’ll see the terms access control and authorization used interchangeably across the industry. According to OWASP, “access control and authorization mean the same thing.” A handful of older sources or highly regimented interpretations split authorization and access control into policy definition and enforcement layers, respectively.
In everyday implementation and across all Descope content, “access control” is synonymous with “authorization.” When you see one, it means the other, too.
Role-based access control (RBAC)
RBAC is the most widely used access control model in production today, and with good reason. It’s simple, easy to manage, and very effective for many use cases. Instead of assigning permissions to individual users (like in DAC above), permissions are assigned to role, and users are assigned to roles. An “Editor” can read and write. A “Viewer” can read. An “Admin” can do anything, including adding or removing new users or assigning roles beneath them.
RBAC is especially useful in cases where roles in an application correspond to roles in an organization. For example, a new employee would get a role that matches their job function, like “Team Member.” In an ideal scenario, permissions they need are already granted to that role, so it’s as simple as ticking a box.
RBAC deployments generally fall into three main categories:
Traditional RBAC is flat, where roles carry permissions, users carry roles, and the two elements never interact in complex ways.
Hierarchical RBAC layers roles by organizational seniority, so a “Manager” role inherits everything a “Team Member” role can do, plus additional permissions.
Constrained RBAC limits how many roles a user can hold simultaneously or which roles can coexist, preventing risky permission combinations.
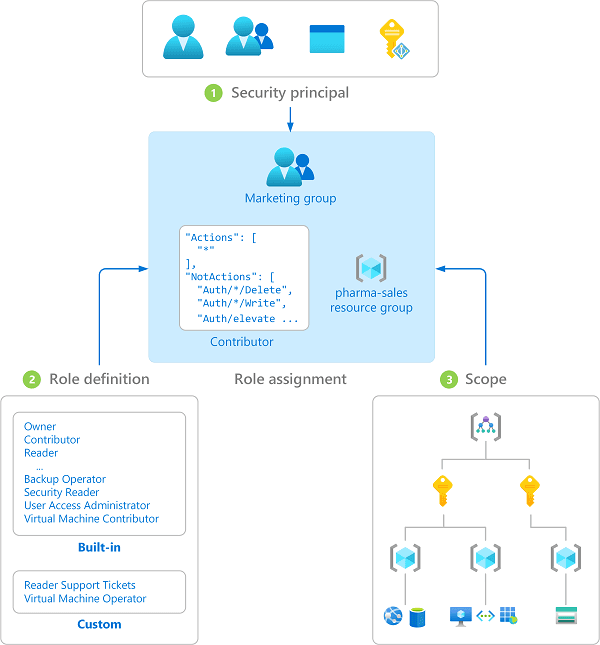
In RBAC, the breaking point shows up at scale. When access requirements include significant diversity, administrators tend to create increasingly narrow roles for edge cases. Recall the example of the new employee above, who receives the “Team Member” role in their onboarding. Imagine they also need access to a database that typically only Managers can see—not all Team Members need access, just this one new employee.
This new role, “Marketing Editor, APAC, Quarterly Reports” makes sense when it’s just for one team and one purpose. But multiplied across departments and organizational touchpoints, and the result is role explosion: an unwieldy sprawl of roles so dense that auditing and maintaining them becomes its own operational discipline.
Role explosion is the clearest signal that it’s time to upgrade to fine-grained access control (FGA). When an organization’s access needs have outgrown what roles alone can express, it’s time for FGA: attribute-based and relationship-based access control.
Fine-grained access control (FGA)
When roles aren’t granular enough to meet an organization’s needs, the next step is fine-grained access control (or fine-grained authorization). FGA is an umbrella term for access control that evaluates multiple conditions rather than relying on a single consideration like a user’s role. Today, two core models fall under FGA: relationship-based access control (ReBAC) and attribute-based access control (ABAC).
Relationship-based access control (ReBAC)
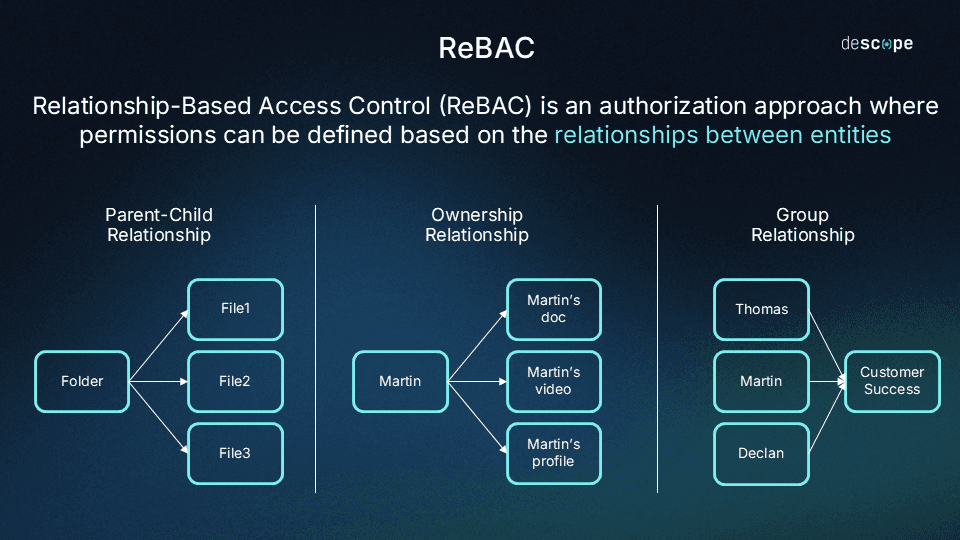
ReBAC shifts the access decision from “what role does this user have” to “what is this user’s relationship to this resource?” Think of it this way: a user who created a document can edit and delete it. A user who was invited to a shared folder containing the document inherits its contents. A team lead can view performance data for their direct reports but not for other teams.
The model essentially works as a graph:
Entities (users, resources, groups, tenants) are nodes
Relationships (ownership, membership, parent-child hierarchies) are edges
Access decisions travel this graph to determine whether a valid path connects the requesting user to the target resource with the required permission. Google’s Zanzibar system, for example, powers access control across Calendar, Drive, and YouTube. It popularized this approach and remains the reference point most modern reBAC implementations draw from.
ReBAC is a natural fit for environments where resources are user-generated and permissions need to vary on a per-resource basis. Think collaboration tools, document management systems, or platforms where different user types need different levels of access to the same end objects.
If reBAC has a tradeoff, it’s the upfront investment. Defining relationship schema, maintaining it as the application matures, and ensuring that implied relationships resolve correctly takes more architectural work. This is why many organizations rely on an external identity vendor to provide the tools and framework for building a reBAC implementation, rather than building from scratch.
Our RBAC vs. ReBAC explainer covers the comparison in more detail.
ReBAC example: You.com
You.com, an AI-powered productivity platform serving both individual users and enterprise teams, provides a practical example of ReBAC at work. The platform includes AI assistants and projects that must be accessible to different users at different permission levels, all within the context of organizations, users, teams.
Using ReBAC, You.com can define access based on how users relate to these resources and to each other:
A user who created an assistant or project owns it and has full control
Teams exist within organizations, and a project can be shared with an entire team
Organization-level super admins inherit administrative access across the teams beneath them
Permissions are inherited through relationships: if a team has edit access to a project, its members do, too
With RBAC alone, You.com would need to create roles for every combination of user type, team, and resource. Instead of granting all members of a team access based on their relationship to the team, RBAC roles would have to be designated with specific permissions.
ReBAC lets You.com model these access controls as relationships (ownership, team membership, organizational hierarchy) without setting up countless roles before query time.
Attribute-based access control (ABAC)
Where ReBAC models relationships between entities, ABAC evaluates properties of the access request itself. Unlike ReBAC, which is largely based on Google’s Zanzibar implementation, ABAC is officially formalized in SP 800-162.
In this Special Publication, NIST defines ABAC as a methodology where decisions are made by evaluating attributes of the subject, object, requested operations, and environment conditions against policy. In more specific terms, these attributes could include:
User attributes (department, clearance, location)
Resource attributes (sensitivity, category, classification)
Action attributes (read, write, delete)
Environmental attributes (time of day, network, device)
Considering these attributes allows policy to express rules RBAC cannot: allowing access to financial reports only for users in the finance department, only during business hours, only from managed devices or via corporate VPN. Each condition is an attribute, and the underlying policy evaluates them in combination.

ABAC’s flexibility comes with a slight tradeoff: opaque governance, or the difficulty of maintaining and auditing policy. The number of possible attribute combinations can grow multiplicatively, and without highly disciplined attribute classification and clear policy ownership, ABAC can become practically unmanageable. Policies may be technically correct but lack clarity for anyone trying to audit or edit them.
In our ABAC vs RBAC explainer, we compare how this tradeoff compares to the lack of granularity in a role-based model.
In real-world scenarios , ReBAC, ABAC, and RBAC often work together. RBAC establishes what a user can do broadly (“this user has the Editor role, so they can create and edit documents), ReBAC can handle resource-level relationships (“this user owns this document, so they can delete it and manage who has access”), ABAC layers on contextual conditions (“but they can only take those actions from a managed device or network”).
Organizations that need fine-grained control often use elements of each, and they don’t necessarily abandon RBAC entirely. Each has a purpose, even if some are less about finesse than others.
Orchestrating access across different models
When a company runs RBAC for baseline permissions, ReBAC for resource relationships, and ABAC for contextual rules, they face a coordination hurdle: How do you enforce consistent access control policy across multiple models, applications, and user bases without fragmentation?
Policy-based access control (PBAC) addresses this at a conceptual level: centrally managed, versioned policies that govern access decisions regardless of the underlying model in question (RBAC, ReBAC, or ABAC):
A policy decision point evaluates whether a request satisfies the applicable rules
A policy enforcement point executes the decision
The value here is consistency and auditability, both elements that can be lacking to varying degrees in our three models. It’s especially vital to have some degree of policy orchestration in regulated industries where demonstrating access control compliance is a fundamental expectation.
The practical implementation of this coordination varies. Some organizations adopt dedicated policy engines with specialized languages like XACML. Others tackle it through identity orchestration: visual or code-based workflows that weave together role, relationship, and attribution checks along with risk signals and third-party actions. This approach offers the most seamless and observable result, but the right path can depend on a number of factors: an organization’s regulatory requirements, technical maturity, and how many moving parts (e.g., third-party risk analysis tools) need to talk to each other.
Ultimately, what matters is that the coordination layer exists and ties loose threads together. Without it, RBAC roles live on one system, ABAC attributes on another, and ReBAC schemas in a third, without one single point of visibility into what’s actually happening or being enforced.
Access control for AI agents
The models above were designed for a world where the entity requesting access is a human with a defined organizational function or role. AI agents break that assumption in ways that are becoming hard to ignore. And, with exponentially increasing adoption, the scenarios documented in IBM’s Cost of a Data Breach Report (in which 97% of AI-related breaches had inadequate access controls ) are likely to explode without intervention.
The problem with AI agents and traditional access control models
An AI agent acts on behalf of a user but is not that user. It operates autonomously (or at least semi-autonomously), chains actions across multiple systems, and can persist long after the authorizing user’s session ends. Give it the user’s own credentials, and it inherits permissions much broader than the task really requires.
The options for revocation are limited and static to the point of being unwieldy. But if you give an AI agent a limited, static service account, it can’t request elevated access when a task demands it. In practice, this leads to risky configurations to avoid hitting obstacles. The OWASP Top 10 for Agentic Applications in 2026 reflects this trending threat: three of the top four risks (agent goal hijack, tool misuse and exploitation, identity and privilege abuse) are fundamentally access control issues.
Where traditional access control models fall short with agents
Early approaches in agentic access control leaned on the barebones primitives of auth frameworks. But the API keys, service accounts, and OAuth scopes typically used in agentic scenarios offer static boundaries that work best for predictable, narrow use cases. A script reading from one endpoint or a bot posting to one channel would be well-suited to these models. But not agents, which need flexibility and agility to complete their diverse tasks.
These models weren’t built for the dynamic nature of agents. An agent that schedules meetings, queries a database, drafts emails, and files developer tickets across multiple services needs credentials scoped per action and time-bound task. Traditional RBAC can assign a role to the agent, but it can’t differentiate between the agent connecting with a particular endpoint and trying to delete an entire production database in the same session.
The rise of purpose-built, scoped agent identity
This gap has driven a shift toward treating agents as a distinct identity type with their own lifecycle, credential model, and access control surface. The response to this challenge looks like this:
Ephemeral credentials scoped to specific actions
Access granted through delegated consent rather than shared credentials
Policy enforcement that accounts for the agent, the authorizing user, and the sensitivity of the downstream resource
Everything auditable at the agent and tool level
This is an obvious clean fit for the FGA concepts discussed earlier. ReBAC can model the relationship between an agent and the resources it’s authorized to touch.
In RAG pipelines, for example, ReBAC-based post-retrieval filtering ensures that an agent only surfaces documents the requesting user is actually authorized to see, preventing data from leaking across user sessions or tenants. ABAC can layer on contextual conditions like time bounds, tenant scope, and user requirements.
Because the entity being gated is autonomous, these scenarios demand tighter scoping, shorter-lived credentials, and more precise logging than human users might typically require. Descope’s Agentic Identity Hub implements these principles as an answer to the unique challenges of agentic access control.
But the broader concept extends beyond any single vendor. As both OWASP and Gartner recommend across multiple trends reports, organizations should take a targeted, risk-based approach. Invest where gaps are greatest while leveraging automation (e.g., developer tooling) where possible.
Also Read: Securing Your APIs With Progressive Scoping
When to use each access control model
The models described in this guide are not mutually exclusive, as we’ve noted above. Most environments above a certain threshold of complexity run a hybrid system, and the question is less about “which model is best” and more “which combination fits the access patterns we’re actually dealing with.”
Access control models compared
The chart below examines the various access control models we’ve discussed in this guide across several dimensions. However, as previously mentioned, all these models can and often do work together.
| RBAC | ReBAC | ABAC |
|---|---|---|---|
Makes decisions based on | User roles | Entity relationships | User, resource, action, and environment variables |
Granularity | Coarse to moderate | Fine | Fine |
Implementation complexity | Low to moderate | Moderate to high | Moderate to high |
Primary scaling concern | Role explosion | Schema maintenance | Attribute sprawl/opacity |
Best for | Stable organizational structures with well-defined roles and functions | Collaborative platforms, user-generated content, hierarchical resources | Dynamic environments, regulated industries, context-dependent access scenarios |
RBAC
This remains the right starting point for most applications. If roles are stable, permission sets are predictable, and there’s no need for per-resource granularity, RBAC on its own may be all that you need. The administrative simplicity and auditability are meaningful advantages.
ReBAC
The inflection point at which FGA becomes attractive is usually one of two things: role explosion or resource-level access requirements. When the first happens, FGA is officially on the table. When the environment aligns with the second, ReBAC is the natural solution. The tradeoff is greater complexity in maintenance, but probably less than managing countless roles.
ABAC
However, when access decisions depend on context that neither roles nor relationships can capture (time, location, device, data type), ABAC fills the gap. ABAC is especially well-suited as a supplemental model, as it can catch all the various conditions the others don’t. It’s perfectly competent on its own, but the risk of opaque (and practically un-auditable) attributes increases if they grow too numerous.
The path most organizations follow uses RBAC for 80% of cases and FGA for the remaining 20% that would otherwise require an unmanageable number of narrow roles. Centralized policy coordination enters the picture when the number of models and enforcement points in play warrants a single view of what’s actually happening.
Ultimately, the “right” access control method isn’t the most granular one available. Just because a model can be very specific doesn’t mean it fits your needs right now. The best choice is the one that actually satisfies the security and operational needs in front of you, while still being manageable for the team you have now.
Implementing access control that fits your needs
Descope provides the tools to implement and orchestrate access control across RBAC, ReBAC, and ABAC without building anything from scratch. Our authorization approaches cover the entire access control framework, from setting up roles and permissions to defining relationship schemas and attribute-based conditions.
For a hands-on walkthrough of how these models work together, this video demonstrates FGA in an IoT device context. For applications running fine-grained authorization at scale, Descope also offers FGA Cache, which accelerates ReBAC and ABAC checks by caching authorization data locally within your cluster.
To explore how Descope provides access control solutions end to end, sign up for a Free Forever Descope account, or connect with like-minded builders on our Slack community, AuthTown.


