

Table of Contents
Don't have the time to read the entire post? Our human writers will be sad, but we understand. Summarize the post with your preferred LLM here instead.
Not every OAuth interaction directly involves a user. When the client is a backend service, a scheduled job, or an AI agent operating under its own identity, there’s no user to redirect, consent screen to display to a human, or user session to manage. The Client Credentials Flow is the OAuth grant type built specifically for that scenario.
This post covers what the Client Credentials Flow is, outlines how it works, shows you when to reach for it (and when not to), examines the security considerations and best practices, and explains how it applies in the context of agentic identity and the Model Context Protocol (MCP).
What is the Client Credentials Flow?
The Client Credentials Flow is one of the core grant types defined in OAuth 2.0, specified in RFC 6749, Section 4.4. It lets a client application exchange its own credentials, typically a client ID and client secret, directly for an access token. No user is involved in the exchange, and no authorization code is generated.
The flow is sometimes referred to as “two-legged OAuth” because only two parties participate: the client and the authorization server. User-facing flows like the Authorization Code Flow introduce a third party (“three-legged OAuth”) in the form of a resource owner, whose consent the client needs to act on their behalf. Client credential skips that step entirely because the client is acting under its own identity, not as a delegate of a specific user.
Because the security model depends on the client’s ability to safely store a secret, the flow is reserved for confidential clients. The spec distinguishes confidential clients (capable of authenticating securely with an authorization server) from public clients (which cannot, typically because they run in environments where credentials would be exposed). Browser-based applications and most native mobile apps fall into the public category and use the Authorization Code Flow with PKCE instead of Client Credentials.
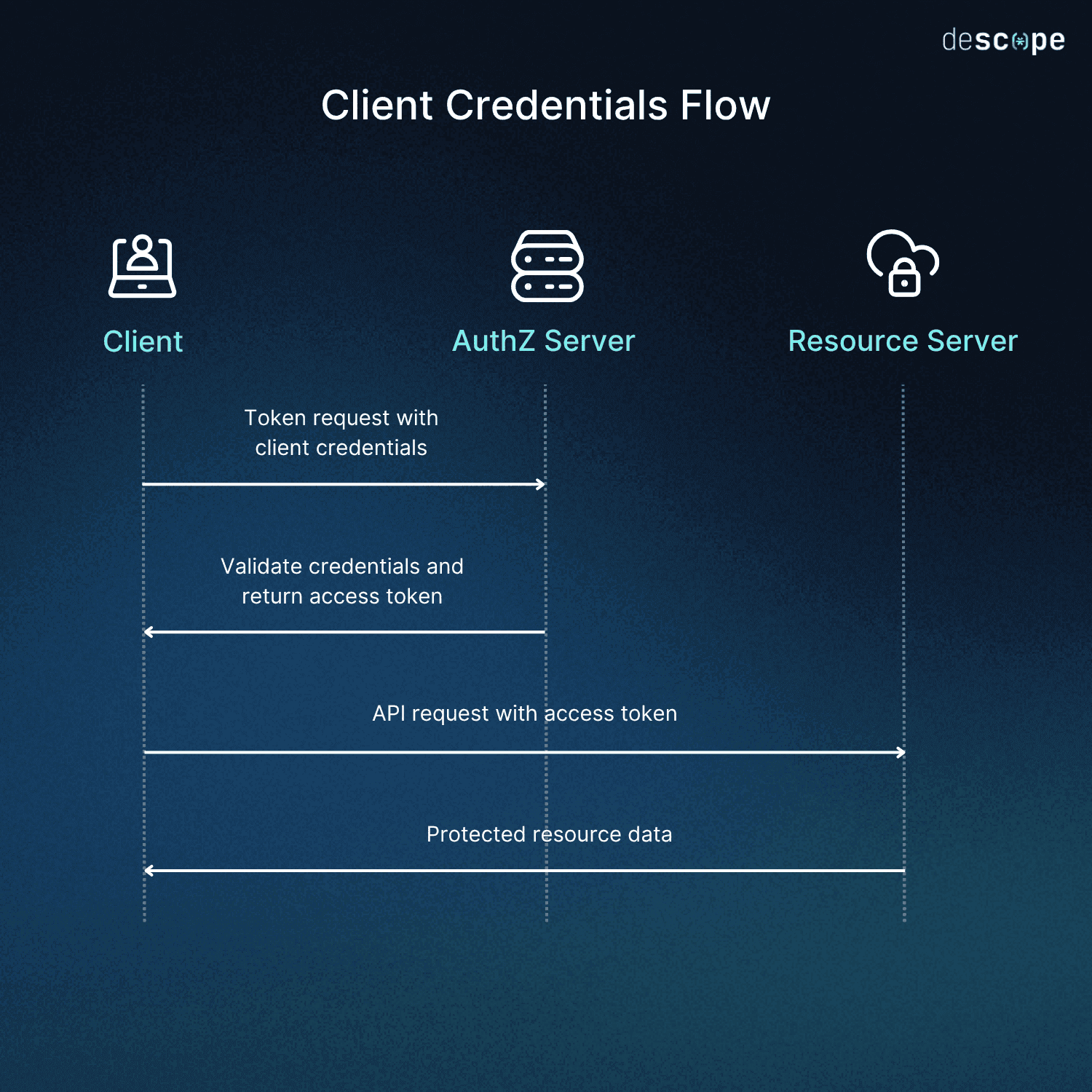
How the Client Credentials Flow works
The flow has just four steps (notably, the initial client registration occurs outside the flow) and zero user interaction in any of them:
Client registration: While not strictly part of the flow itself, the application registers with the authorization server, typically once, and receives a client ID and client secret. This step happens out-of-band before the flow runs.
Token request: The client sends a POST request to the authorization server’s token endpoint with
grant_type=client_credentials(the parameter that tells the authorization server which OAuth flow is being requested), authenticating itself with its credentials. The most common authentication method isclient_secret_basic, which transmits the client ID and secret in an HTTP Basic auth header. The request can also include ascopeparameter (the list of permissions the client is requesting).Validation: The authorization server verifies the credentials and confirms the client is permitted the requested scopes.
Token response: The server returns an access token (the spec does not specify a token format), which is often a JSON Web Token (JWT) containing the client’s identity and granted scopes, along with the token type and expiration.
API call: The client uses the access token as a bearer token in the
Authorizationheader (the standard HTTP header for authentication credentials) to call the protected resource server.
It’s worth noting that no refresh token is issued in this flow. The RFC explicitly states that a refresh token should not be included with a client credentials response, as the client already has the credentials it needs to request a new access token whenever it wants one. A refresh token would add no value.
When to use the Client Credentials Flow
The Client Credentials Flow is the right choice whenever the access token represents the application itself rather than a specific user. Common scenarios include:
A backend service calling another backend service
A scheduled job or task accessing an API
A CLI (Command-Line Interface) tool that authenticates itself rather than as a user
Microservices in an internal mesh authenticating to one another
An AI agent calling a tool or API where no specific user identity is being represented in the auth context
The flow is the wrong choice any time a specific user’s identity or consent is part of the action. If your application needs to read a particular user’s data, write on their behalf, or follow their consent decisions, you shouldn’t use the Client Credentials Flow. Instead, the Authorization Code Flow (with PKCE) preserves the user’s delegation choices. Using Client Credentials in those situations erases the user from the audit trail and bypasses delegation entirely.
Remember that the question both of these flows are trying to resolve is not whether a human triggered the action. In many scenarios, a human might start the process that kicks off a backend job, and that job might run for hours (or days, or longer). The question these flows answer is whose identity the access token represents when the call is made. If the answer is “the application itself,” Client Credentials Flow is correct. If the answer is “a specific user,” it’s Authorization Code Flow.
Client Credentials Flow security considerations and best practices
The Client Credentials Flow trusts that the client can keep a secret. Everything that follows is about protecting that assumption and limiting the blast radius if that secret leaks.
Do
Treat the client secret as a high-value credential: Store it in a secrets manager, inject it at runtime, and never commit it to source or include it in client-side code.
Keep access tokens short-lived: There is no refresh token in this flow, but re-issuance is fast, so favor brevity over longevity.
Request only the scopes you need: Configure the authorization server to filter requested scopes against what the client is actually permitted to receive.
Bind tokens to specific resource servers: Use the audience claim (
aud) so a token issued for one service cannot be replayed against another. OAuth Resource Indicators (RFC 8707) define a standard way to specify the intended audience at token request time.Use stronger client authentication when assurance matters: The
client_secret_basicmethod is the baseline for the spec, not the recommendation. For higher-assurance environments,private_key_jwt(an authentication method where the client signs a JWT with its private key) and mutual TLS (a more common pattern in modern service meshes when combined with SPIFFE/SPIRE) avoid sending a shared secret across the wire by using asymmetric cryptography or client certificates instead.Rotate client secrets on a schedule and after any suspected compromise: Make sure the authorization server exposes a revocation endpoint so leaked credentials can be invalidated immediately.
Don’t
Don’t use the Client Credentials Flow as a substitute for user-delegated access: If a specific user’s identity matters to the call, use Authorization Code Flow instead.
Don’t embed client secrets in mobile apps, single-page apps, or browser code: Confidential client really means confidential, no exceptions. If the secret can be extracted by a determined user, the security model isn’t reliable. Use a different method.
Don’t issue long-lived tokens to avoid the cost of re-issuance: The cost is negligible, which is why refresh tokens are excluded from the spec. The leak-token window should be minimal to keep the blast radius insignificant.
Don’t share a single client identity across multiple entities if you want reliable auditing: Per-instance attribution will pretty much go out the window the moment you bind more than one agent or service to a single client identity. Distinct clients give you distinct audit trails.
Don’t skip audience binding: A token without an
audclaim is a token that can wander indiscriminately between resource servers without scrutiny, which defeats the point of scoping.Don’t leave stale credentials provisioned: Decommission OAuth clients as part of service retirement and staff offboarding. Credentials that outlive the associated processes are an exploitable attack surface.
The Client Credentials Flow in MCP-based agentic identity
The core MCP authorization specification focuses on user-delegated flows, mandating OAuth 2.1 with PKCE for interactive scenarios (the most common use case by a significant margin). Machine-to-machine (M2M) auth is covered separately by an authorization extension for the Client Credentials Flow. This extension uses MCP’s standard capability negotiation: clients declare their support in their initialize request capabilities (the handshake message that begins an MCP session), and servers advertise support in their response.
The MCP OAuth Client Credentials extension exclusively applies to cases where clients authorize to MCP servers without a user in the loop. The client is software acting under its own identity, and the MCP server validates a token issued for a non-human identity (NHI) rather than a human. AI agents fit in this set when they are running in a non-interactive context: background services calling MCP tools on a schedule or in response to events, CI/CD pipelines that invoke MCP servers as a function of automated workflows, server-to-server integrations connecting two backend systems, or worker/daemon processes needing persistent access to MCP resources.
The extension supports two credential formats and recommends JWT Bearer Assertions (RFC 7523) over the less secure option, client secrets. With JWT Bearer Assertions, the client signs a short-lived JWT with its private key and presents it as proof of identity, and the authorization server validates the signature using the client’s registered public key. Client secrets, on the other hand, should only be used for simple deployments. JWT Bearer Assertions are short-lived and do not require transmitting the signing key; client secrets are long-lived and can enable attackers to silently authenticate as your application until the secret is rotated.
Notably, the extension does not cover when an MCP server acts as a proxy for a third-party API, and then calls that API on behalf of a user. The upstream call is user-delegated and uses separate mechanisms like OAuth Token Exchange. The current MCP authorization spec’s best practices explicitly forbid token passthrough in such a case, citing risks like the circumvention of downstream security controls (rate limiting, request validation, broken audit trails). The Client Credentials Flow is the right tool for genuine M2M scenarios, but should not be treated as a workaround for user-delegated upstream calls.
Provisioning, scoping, and policy
One thing should be clear from the above explanation: the steps of the Client Credentials Flow itself don’t meaningfully change in agentic contexts. What’s different is how the surrounding pieces fit together: how clients get their credentials in the first place, how scopes are defined for the tools the client wants to call, and how policies govern who is allowed to do what.
Provisioning
Manual pre-registration works when the population of clients is known, stable, and small. It doesn’t work when agents are dynamically spun up, decommissioned, or numerous. Dynamic Client Registration (DCR) is the most relevant pattern for the Client Credentials Flow, since it can issue confidential clients a client ID and secret programmatically. The MCP authorization spec also points to Client ID Metadata Documents (CIMD) as the preferred default for client registration in MCP, but CIMD is designed for public clients (those that can’t keep a secret) running Authorization Code Flow with PKCE. For agents authenticating under their own identity using this flow, DCR is the registration pattern to use, ideally hardened against the open-registration risks that come with it.
Scoping
Coarse OAuth scopes with blanket permissions (i.e., read and write) leak a blast radius far too wide for autonomous agents to be trusted with. The MCP authorization spec mandates scope minimization, and the practical resolution is one scope per MCP tool or tool group so that a token can be tightly bound to the specific capability the client needs rather than the whole API surface.
In the Client Credentials Flow, the client is provisioned with a fixed set of allowed scopes at registration time, which makes scope design at that step an even more critical security consideration than in non-agentic contexts.
Policy
Here is where the Client Credentials Flow presents a significant constraint. Authorization server policies that evaluate access controls, user roles, tenant membership, or other context at token issuance are designed around the user consent flow, not M2M auth. They do not apply to tokens issued via Client Credentials because there is no user in the loop to evaluate. Scope governance for client credentials happens at client registration time (which, as described above, defines which scopes a given client is allowed to request) rather than at token issuance time. Runtime enforcement still belongs to the MCP server, which validates the token’s scopes against the requested operation. In contrast, comprehensive agentic identity solutions like Descope’s Agentic Identity Hub handle broader policy decisions by treating each agent as a first-class, non-human identity with its own associated user, tenant, scopes, and audit trail, so attribution and access decisions remain observable even when the flow itself carries no user context.
Using Client Credentials Flow securely
The Client Credentials Flow is the OAuth standard for M2M authentication. It fits neatly when the access token represents an application itself rather than when it acts as a delegate for a human user. These jobs (backend service composition, CLI tool functions, microservice operations) match the flow’s well-defined space. And the flow itself is largely unchanged in its small, tightly specified mechanics even with the rise of agentic systems.
What has changed are the decisions around it. MCP’s published authorization extension is sufficient to achieve the flow’s purpose, but production deployments require more than the baseline: registration patterns that scale to dynamic agent populations, scopes defined at the granularity of individual tools, and policy enforcement that accounts for the absence of user context in the token. None of this is novel, but all of it operates at the edges of the flow rather than inside it.
If you’re working on an AI project that needs M2M auth, agentic identity, or a combination of both, the Descope Agentic Identity Hub is built around these exact layers. See agentic use cases in action, join the AuthTown dev community, and sign up for a Free Forever Descope Account to secure your MCP servers or agents without rebuilding the surrounding infrastructure.



