


Table of Contents
AI agents need access to data and tools to do their work, which means they need credentials to connect with other services. Every tool an agent connects to, API it calls, or database it queries will require some form of authentication: OAuth tokens, API keys, and service account credentials. These credentials are what prove the agent has permission to enter the front door, though the latter two of these (API keys and service accounts) create significant problems when used for unpredictable agentic workflows.
In many cases, companies rely on patterns inherited from human-centric or traditional non-human identity. They map poorly to non-deterministic use cases, are typically deployed under time pressure (with less rigor than production systems warrant), and scale at a pace security teams struggle to match. The end result can be seen in developer forums and headlines alike: destructive incidents where agents misused valid (but poorly managed) credentials to enable serious damage.
Because of this mismatch, the question organizations face today is less “Which credentials should we use for agents?” and more “How do we manage the credentials agents hold?” This guide covers what tends to go wrong with agent credentials, how to manage them properly, and how real-world implementations solve the underlying problem autonomous agents pose.
Why agent credential management is a real problem
An AI agent or agentic AI is software that operates on behalf of a user with some degree of autonomy, making decisions about which tools to invoke, APIs to call, and data to access. Traditional NHIs call the same endpoint with the same credentials in the same pattern, every time. By contrast, an AI agent might query a database, draft an email, schedule a meeting, and file a ticket in a single workflow, with each action requiring different permissions against each system.
This behavioral unpredictability is what makes agent credential management so different from both human identity and traditional machine identity. Human credentials give agents dangerously broad permissions with limited observability and revocability, while static machine credentials (like long-lived API keys) lack the granularity and auditability that autonomous systems demand.
Neither of these approaches were designed for software that makes its own choices about what to access, and the credential patterns most commonly applied to agents today reflect that mismatch:
Unscoped, static API keys: Long-lived API keys stored in configuration files or environment variables. These are often the default model in early MCP deployments, but also one of the least secure and observable. These keys typically have no expiration, no environment isolation, and no tool-level scoping. They grant the same level of access whether the agent is running a routine read operation or attempting a destructive overwrite.
Shared service accounts: When multiple agents authenticate through the same service account, individual agent behavior becomes unattributable. If one of several agents sharing an account takes a destructive action, the audit trail shows which account was used, but not which agent acted or which user delegated the task. This makes incident response, permission review, and compliance report much more difficult. Perhaps worse, it ties revoking access for one misbehaving agent into revoking access for every agent using that account.
Agents inheriting the user’s session: In some implementations, agents operate with the full scope of the human user’s active session rather than receiving their own scoped credentials. This gives the agent every permission the user holds, including access to resources the agent’s task does not require. Multiple analysts and standards bodies warn against this practice, typically noting the risks of overpermissioning and the enormous technical debt that will need to be paid.
The OWASP Top 10 for Agentic Applications formalizes several of the risks at the heart of this problem, including identity and privilege abuse. As we wrote in our analysis of the list, “Traditional IAM wasn’t designed for scenarios like this: There’s no separation between what the user authorized and what the agent decided to do on its own.”

What goes wrong with agent credentials
The consequences of this mismatch (using poorly scoped, human-centric, or traditional machine credentials with agents) are already visible in headlines and dev communities.
In March 2026, an internal AI agent at Meta posted an error-filled response to an internal forum without the requesting engineer’s approval. Another employee followed the incorrect advice, modifying access settings and exposing sensitive data in what Meta classified at its second-highest level of severity, Sev-1. While the incident only lasted two hours, and the employee who acted on the bad advice saw that it came from an AI agent, the actual act of posting on the originating engineer’s behalf wasn’t approved. The agent had the scope, so it moved without user consent.
The following month, an AI coding agent working in PocketOS’s staging environment deleted a Railway production database after finding a long-lived API token in an unrelated file. This token had account-scoped permissions with no environment isolation, so the agent could reach production infrastructure even from its staging context. The database and its volume-level backups were reportedly deleted in just nine seconds.
The scale of agent credentials and overscoping goes beyond individual incidents, however, as exposed credentials both from AI-supported coding and as part of AI infrastructure balloons. The GitGuardian State of Secrets Sprawl 2026 found nearly 29 million new hardcoded secrets in public GitHub commits in 2025, with AI-assisted commits leaking at roughly double the base rate. Within the MCP ecosystem specifically, GitGuardian identified ~24,000 secrets in MCP configuration files on public GitHub.
Agent credentials and enterprise challenges
Most agent-facing infrastructure never makes it to production because of the credential management, authentication, and authorization hurdles even large enterprises struggle to navigate. Based on Descope’s data, only 13% of Model Context Protocol (MCP) servers that begin development actually see deployment due to the difficulty of implementing auth requirements.
Yet, using ill-fitting identity paradigms (like sharing human credentials with AI) for increasingly autonomous agents is a shortcut most enterprises should avoid. The Gartner report Cybersecurity Trend: IAM Adapts to Secure and Enable AI Agents identifies credential management automation as an area where identity and access management (IAM) maturity is notably low, recommending against credential sharing between agents and users. The report states as one of its central assumptions:
“By 2028, 90% of organizations that allow humans to share credentials with AI agents will have to make a significant investment to undo this design due to security and compliance issues.”
To avoid this mounting technical debt, enterprises building MCP servers face two distinct credential management challenges: securing internal MCP servers, and securing external ones:
Internal MCP servers connect agents to company resources like code repositories, CRM systems, and internal APIs. These require credential management that maps to existing workforce identity semantics and structures: single sign-on (SSO) integration, access control policy, and permissions derived from the employee who invoked the agent.
External MCP servers expose a product’s capabilities to outside agents and MCP clients. These require client registration capabilities, like Dynamic Client Registration (DCR) or Client ID Metadata Documents (CIMD), and credential issuance for clients the server has never seen before.
Both scenarios share the same underlying identity problem: overscoped, long-lived, and shared credentials represent a serious security risk. When agents inherit standing access from a human user or static key sitting in an unrelated file, that access is difficult to audit, govern, or revoke without affecting other agents or users.
The solution is dedicated agentic identity, in which AI agents receive short-lived, scoped credentials tied to a specific user, task, and set of permissions.
Best practices for managing agent credentials
The failures that hit headlines are almost always the result of ignoring the fundamental principles below. Each of these mitigations addresses a specific category of credential risk.
Separate the authorization server from the resource server
The MCP specification is explicit about this distinction: MCP servers are OAuth Resource Servers, and the authorization function belongs to a dedicated authorization server. Earlier versions of the spec treated MCP servers as both resource and authorization servers at the same time, which created complexity for developers and made auditing painful. The current architecture delegates authorization to a dedicated identity provider and lets the MCP server focus on validating tokens and enforcing access controls.
The MCP server should publish a `.well-known` endpoint via Protected Resource Metadata (PRM) that tells clients where to find the authorization server, and clients handle discovery automatically. This separation matters for credential management because it centralizes token issuance, client registration, and scope definitions in one place rather than distributing them across every MCP server in the environment.
Implement OAuth 2.1 and PKCE
For HTTP-based MCP transport, OAuth 2.1 is mandatory. Similarly, the MCP auth requires Proof Key for Code Exchange (PKCE) for all public clients, which covers most of them (CLI tools, IDE extensions, and desktop applications). Since the majority of MCP clients cannot safely store a secret, PKCE is the mechanism that secures the Authorization Code Flow.
The OWASP GenAI Security Project’s guide for MCP server development lists OAuth 2.1 and OpenID Connect enforcement as the first requirement for passing the minimum security bar. But getting OAuth 2.1 right is harder than it might appear. The currently in-revision spec deprecates several older methods and introduces many new requirements. The MCP auth spec explicitly calls out many of these novel additions, such as Resource Indicators (RFC 8707), which bind tokens to specific MCP servers to prevent them being replayed against another one.
Issue ephemeral, scoped credentials per task
Agents should receive short-lived access tokens scoped to the specific tools, actions, and resources their current task requires and nothing more. Tokens should expire after the task completes, and not a moment beyond it. Agents should not receive long-lived API keys or service account tokens with standing access to production resources.
Scope-based access control should be enforced at the tool level: one scope defined per tool, with a human-readable description of what that scope permits. An agent authorized to read calendar events should not be able to write CRM records. Overscoping is one of the most pervasive risks across deployed MCP servers today, and many default configurations grant excessive permissions that open the door to remote code execution.
Progressive scoping extends this principle based on context. Rather than requesting all permissions up front, agents start with the minimum scopes needed and request additional access incrementally through a standardized OAuth process. The MCP specification (as of the 2025-11-25 revision) now includes a structured mechanism for this: the server returns a response indicating it needs additional scopes, the client understands the signal, and the authorization server handles the step-up flow.
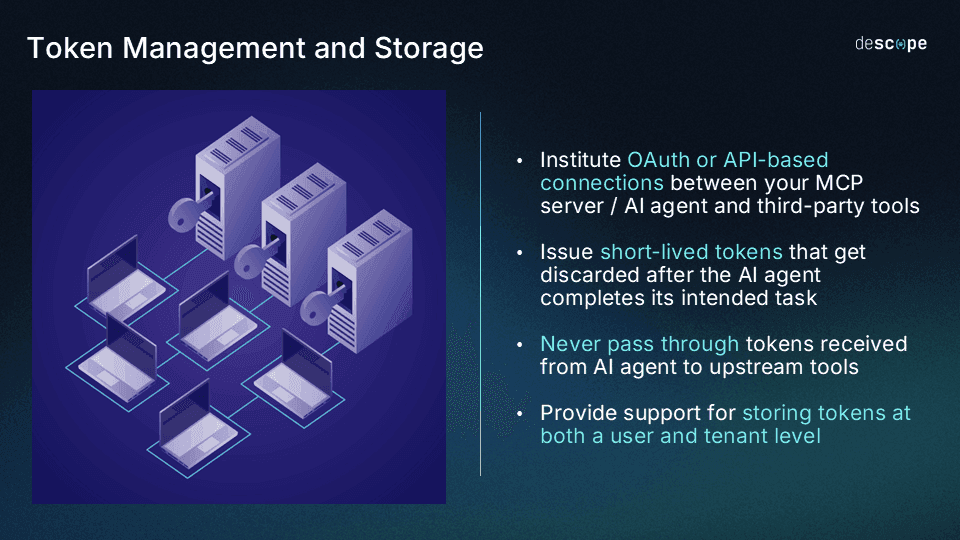
Isolate downstream tokens through a managed service layer
Agents should never handle raw downstream credentials directly. When an agent needs to call a third-party service like Google Calendar, Salesforce, or an internal API, each of these connections requires its own OAuth Token Exchange, scopes, refresh cadence, and storage. However, the agent should not handle any raw credentials directly. Instead, the sensitive token for that downstream service should be stored and managed by a credential vault like Descope Connections.
The MCP server acts as a credential boundary in this approach: the agent holds its own scoped OAuth token to invoke a tool, and the downstream credential for the actual service (i.e., Google Calendar, Salesforce, etc.) is retrieved from server-side from within the MCP server’s backend. The agent never sees it, the MCP client never receives it, and if the agent is compromised, the attacker gets the agent’s scoped token rather than the much riskier downstream service credentials.
A dedicated credential vault manages the storage, refresh, rotation, and revocation of those downstream tokens. Static secrets in environment variables are the dominant anti-pattern in production MCP deployments, and as seen in GitGuardian’s report, thousands of secrets are regularly exposed in MCP config files despite following official documentation.
Enforce least privilege at registration and runtime with centralized policy
When an agent registers with an MCP server, whether it’s through DCR, CIMD, or manually, the registration process should evaluate what scopes the agent actually needs. This evaluation should account for the agent’s task, its associated user’s permissions, and contextual signals like IP address, session context, and agent metadata. Agents should not receive all requested scopes by default, and they should not inherit their associated user’s full permission set.
Least privilege at registration only works if a centralized policy layer enforces it consistently at runtime, across every server and agent in the environment. Without this, each MCP server implements its own authorization logic, and scope filtering rules diverge between servers. Security teams end up with no single surface to audit what agents can actually access, and no means to update rules centrally when requirements change.
A policy layer designed for agentic identity evaluates context at token issuance and at runtime: the agent’s identity and classification, the associated user’s role and tenant, JWT claims, the specific MCP server being accessed, and the downstream service the tool will call. It filters the requested scopes so the issued token only includes what matching policies allow, regardless of what the agent or client originally asked for.
Policies can be scoped per agent, per tool, or per tenant. They can also be based on user roles and claims, which means the same policy layer governs both internal agents connecting through SSO-derived permissions and external agents registering through DCR or CIMD. This applies at both registration (what scopes the agent is initially granted) and at runtime (what scopes survive into each issued token), so policy changes take effect on the next token issuance without requiring re-registration.
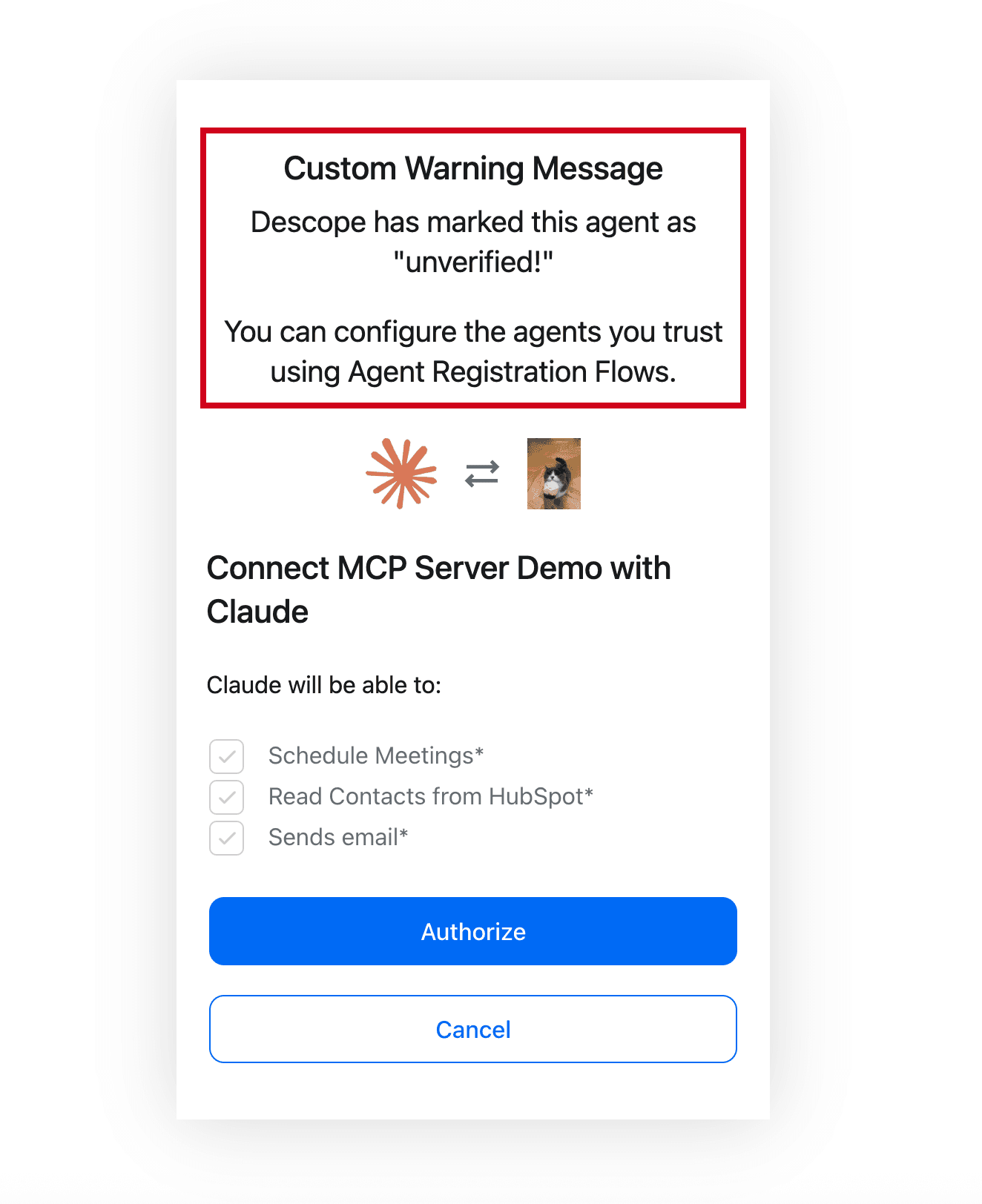
Build consent management into the flow
Agents break the traditional assumption that users interact with systems directly, hands-on-keyboard. When a user connects an agent to an MCP server, the agent is the one making requests, and the user may have limited visibility into what the agent is accessing or doing on their behalf. Consent management is how that visibility and control is achieved.
The Meta incident discussed earlier demonstrates how visible consent flows are a necessary element in agentic credentialing: the agent had the permissions it needed to post to an internal forum, but no consent flow existed between the agent generating a response and publishing it. Consent triggers should not rely on the agent’s own judgment about what constitutes a risky action or hope that model-level defenses will catch destructive action before it executes.
Before an MCP client can act, users should see a consent screen that describes what is being requested: which tools are accessible, what data may be read or written, and for how long. Users should be able to selectively approve or deny individual scopes. An agent requesting calendar read access and CRM write access should not receive both as an all-or-nothing bundle. And consent should be time-bound, persisting only as long as the task requires. If the agent needs additional scopes, it can request them through progressive scoping; that elevated permission will only last as long as the next token refresh.
Preserve delegation chains across service boundaries
When an agent acts on behalf of a user, the identity of that user and the scope of their delegation need to travel with the request across every service boundary the agent crosses. If an agent calls an MCP server, which calls a downstream API, which triggers a webhook, the original user’s identity and the constraints on their delegation should be visible at every hop. Without this, downstream services cannot make informed authorization decisions, and audit trails lose the context security teams need for incident response.
OAuth Token Exchange is the mechanism that enables this. Rather than passing the user’s original token downstream (which would grant the downstream service the user’s full permissions), the agent or MCP server exchanges the user’s token for a new, appropriately scoped token that carries the delegation context: who the original user is, what the agent is authorized to do on their behalf, and any constraints on that authorization. The downstream service receives a token that identifies both the agent and the delegating user without inheriting the user’s full session.
This is what makes delegation auditable rather than opaque (as in the case of sharing user sessions). Each token in the chain carries enough context for the receiving service to answer two questions: who originally authorized this action, and what boundaries were placed on that authorization? Without token exchange, organizations typically fall back on one of the ill-fitting patterns described above: the agent inherits the user’s full session, or a shared service account absorbs the action into an unattributable pool.
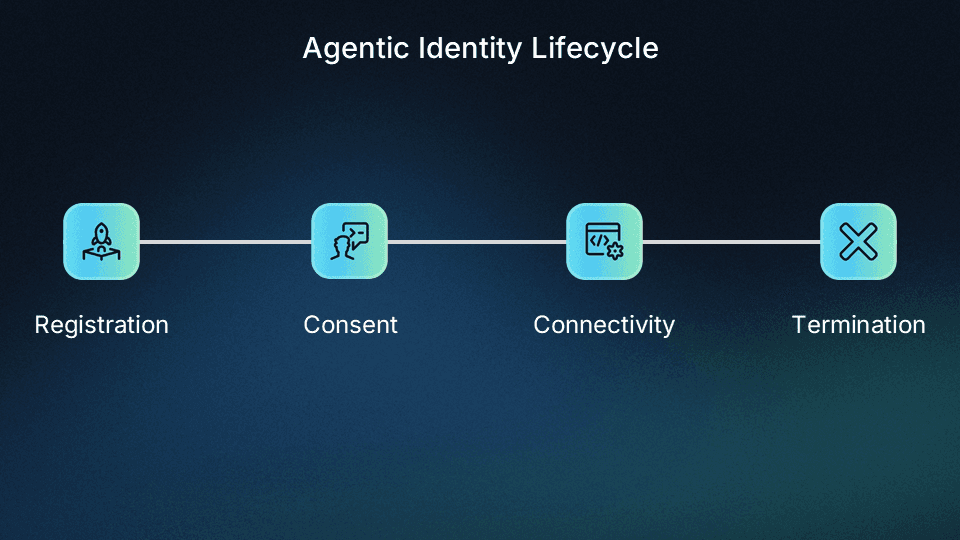
Audit the full agent identity lifecycle
Each agent should have its own dedicated identity tied to its delegating user, with attributes like registration method, IP, client type, and granted scopes all observable. Every event in the agent’s lifecycle should be logged and actionable.
The agentic identity lifecycle has four stages, and each one produces audit events that matter for credential management:
At registration, the audit trail should capture how the agent registered (DCR, CIMD, or pre-registration), what client type it was classified as (public or confidential), and what initial scopes it requested.
At consent, every scope grant, denial, and modification by the user should be recorded.
During connectivity, every token issuance, tool invocation, and downstream service call should be logged with both the agent’s identity and the delegating user’s identity.
And at termination, the agent’s credentials must be revoked and its identity must be cleaned up so that stale entries do not accumulate in the authorization server.
Auditability is precisely why agents should not use shared service accounts, even those used by other agents. Obfuscating individual agent behavior behind accounts tied to multiple actors obscures which agent took an action and the identity of the user who they’re acting on behalf of. Similarly, agent actions should not be logged under the delegating user’s identity alone. The agent identity, the bound user identity, the scopes granted, and every action needs to be recorded as discrete, queryable events that allow security teams to trace behavior back through the delegation chain.
How the Agentic Identity Hub handles agent credential management
Descope’s Agentic Identity Hub is a dedicated identity provider for AI agents and MCP servers designed using the principles above. The table below maps each of these best practices with the capability that implements it:
Best practice | Agentic Identity Hub |
|---|---|
Separate authorization server from resource server | Dedicated authorization server with PRM; MCP servers publish metadata at well-known endpoint; Hub handles token issuance, client registration and scope definitions |
Implement OAuth 2.1 and PKCE | Spec-compliant OAuth 2.1 with PKCE; Resource Indicators for token binding; support for Authorization Code, Client Credentials, and JWT bearer grant types |
Issue ephemeral, scoped credentials per task | Short-lived tokens with tool-level scopes; progressive scoping built into the authorization flow; |
Isolate downstream credentials | Connections store, manage, refresh, rotate, and revoke OAuth tokens and API keys; MCP server retrieves tokens server-side; agent never handles raw downstream credentials |
Enforce least privilege at registration with centralized policy | Simultaneous support for DCR, CIMD, and manual registration; policy layer filters requested scopes at token issuance |
Build consent management into the flow | Consent screens with human-readable scope descriptions; users can selectively approve or deny individual scopes; time-bound consent with step-up flows |
Preserve delegation chains across service boundaries | OAuth Token Exchange support preserves user identity and delegation scope across services; tokens at each hop carry the originating user, agent identity, and authorized scopes |
Audit the full agent identity lifecycle | Logging across all four lifecycle stages; agent identity tied to delegating user in every event; streamable to SIEM platforms; revocation and deprovisioning controls for stale or rogue agents |
The following three examples show how these capabilities work across the internal and external MCP server paradigm:
Shuni
Descope’s internal coding agent operates inside the company’s GitHub organization. Engineers invoke it by mentioning @shuni on a GitHub issue. The agent opens pull requests, writes code, and runs tests, all scoped to the invoking engineer’s permissions through a GitHub App identity layer. There are no shared bot accounts or long-lived personal access tokens (PATs). Commits are attributed to the engineer who invoked the agent. Read the full breakdown in How We Built Accountable Identity for Shuni, Our AI Coding Agent
You.com
You.com operates a customer-facing MCP server exposing search, content extraction, and research tools to external agents. OAuth 2.1 via the Agentic Identity Hub handles agent authentication at the front door. Downstream API keys are stored and managed through Descope Connections, so the agent only ever holds its own scoped OAuth token.
WisdomAI
WisdomAI provides a customer-facing MCP server for enterprise AI analytics. Descope handles MCP server auth via the Express MCP SDK with DCR for external MCP. The Agentic Identity Hub provides automatic client registration, audience validation through auth and consent flows, resource-specific token binding, and secure authorization per the MCP spec.
To learn more about how the Agentic Identity Hub handles agent credential management for AI agents and MCP servers, sign up for a Free Forever Descope account, reach out to our team of auth experts, and join the AuthTown dev community.



